
《React 面试题》
概念
Q1:React Portals 有什么用
难度:⭐
答案
React Portals 是 React 提供的一种机制,用于将子组件渲染到父组件 DOM 层次结构之外的位置
它在处理一些特殊情况下的 UI 布局或交互时非常有用
以下是一些使用 React Portals 的常见情况:
在模态框中使用
当你需要在应用的根 DOM 结构之外显示模态框(对话框)时,React Portals 可以帮助你将模态框的内容渲染到根 DOM 之外的地方,而不影响布局
处理 z-index 问题
在一些复杂的布局中,可能存在 z-index 的层级关系导致组件无法按照预期的方式叠加显示
使用 React Portals 可以将组件渲染到具有更高 z-index 的容器中,以解决这些问题
在全局位置显示组件
如果你希望某个组件在页面的固定位置显示,而不受父组件的定位影响,React Portals 可以将该组件渲染到 body 或其他容器中
在动画中使用
当你需要在页面中的某个位置执行动画时,React Portals 可以帮助你将动画的内容渲染到离该位置更近的 DOM 结构中,以提高动画性能
基本使用
1 | import React from 'react'; |
Q2:React18有哪些更新
难度:⭐
解析
并发模式(Concurrent Mode):
并发模式是 React 的一个大型功能更新,它允许 React 在渲染时更好地管理优先级和资源并发模式可以让 React 在长时间渲染的过程中保持应用的响应性,通过中断渲染工作和重新开始的能力,可以优化性能并减少延迟
更新 render API:
React 18 中的新renderAI 被设计来支持并发功能换句话说,通过使用新的
createRootAPI 替代ReactDOM.render, 可以开启 React 应用的并发特性自动批处理(Automatic Batching):
批处理是一种合并多个状态更新,以减少多余渲染次数的优化技术在 React 18 中,所有的状态更新(无论它们源自事件处理、Promises、setTimeout等)都会自动批处理,而在以前,React 只会在合成事件和生命周期函数中自动批处理更新
Suspense 支持 SSR(Suspense for Server Side Rendering):
在 React 18 中,Suspense组件得到了 SSR 的官方支持这意味着你现在可以使用
Suspense来延迟渲染组件的一部分,直到必要的数据加载完成,即便这个组件是在服务器端渲染的startTransition:
startTransition是一个调度一个不紧急更新的新方法这可以告诉 React 某些更新可以延后执行,让用户不会感受到卡顿,并且保证更重要的更新(如输入)可以优先处理
useTransition:
useTransition钩子允许你在组件中标记状态更新和组件转换你可以使用它来通知 React,某些更新具有较低的优先级。它返回一个数组,其中第一个值是一个布尔值,指示低优先级更新是否正在发生,第二个值是
startTransition的包装函数useDeferredValue:
这个钩子接受一个值,并返回一个延迟版本的该值这对于保持大型列表或表格的响应性非常有用,即使在我们等待这些渲染数据时,用户仍然能够继续做其他操作,如输入
useId:
useId是一个钩子,用来生成稳定、服务端和客户端都能保持同步的唯一标识符,这个功能主要解决在服务端渲染的应用中处理 ID 生成的问题提供给第三方库的 Hook:
React 18 引入了一些新的钩子,如useSyncExternalStore和useInsertionEffect等,专为第三方库设计,以便更好地集成并发模式和新特性
答案
- 并发模式
- 更新 render API
- 自动批处理
- Suspense 支持 SSR
- startTransition
- useTransition
- useDeferredValue
- useId
- 提供给第三方库的 Hook
Q3:react 和 react-dom 是什么关系
难度:⭐
答案
react 和 react-dom 是 React 库的两个主要部分,它们分别负责处理不同的事务
它们之间的关系可以理解为:
react这是 React 库的核心部分,包含了 React 的核心功能,如组件、状态、生命周期等
它提供了构建用户界面所需的基本构建块
当你编写 React 组件时,你实际上是在使用
react包react-dom这是 React 专门为 DOM 环境提供的包,它包含了与浏览器 DOM 相关的功能
react-dom
提供了用于在浏览器中渲染 React 组件的方法,包括ReactDOM.render在 Web 开发中,react-dom` 被用于将 React 应用渲染到浏览器的 DOM 中
基本上,react 和 react-dom 是为了分离 React 的核心功能,以便更好地处理不同的环境和平台
这种分离使得 React 更加灵活,可以适应不同的渲染目标,而不仅仅局限于浏览器环境。
在使用 React 开发 Web 应用时,通常会同时安装和引入这两个包:
1 | npm install react react-dom |
然后在代码中引入:
1 | import React from 'react'; |
在上面的例子中,react 库提供了 App 组件的定义,而 react-dom 库提供了 ReactDOM.render 方法,用于将组件渲染到 HTML 页面中
这种分工让 React 在不同平台上能够更灵活地适应各种渲染目标
Q4:为什么 react 需要 fiber 架构,而 Vue 却不需要
难度:⭐⭐⭐⭐
答案
React 和 Vue 都是现代前端开发中非常流行的库/框架,它们以不同的方式实现更新和渲染机制,以提供高效且响应式的用户界面
React 的 Fiber 架构和 Vue 的响应式系统设计理念在解决特定问题和优化渲染机制上有着各自的目标和策略
下面,我们来探讨为什么 React 需要引入 Fiber 架构,而 Vue 没有采用类似的方案。
React 的 Fiber 架构
Fiber 架构是 React 16 中引入的一个重大更新,旨在解决大型应用的性能问题以及一些与异步渲染相关的挑战
Fiber 架构的关键目标包括:
增强组件的渲染和更新性能:
通过实现任务的分割和优先级调度,Fiber 架构使得 React 能够暂停、中断、恢复和重用渲染工作
这对于提高复杂应用的性能,特别是在动画、布局和手势等需要快速响应的场景中,非常关键
提升应用的响应性:
通过引入异步渲染能力,React 可以在长时间的渲染任务中更好地控制主线程,避免界面卡顿,从而保持应用流畅并快速响应用户输入
更灵活的架构:
Fiber 架构给 React 带来了更多的可能性,如并发模式、Suspense 等,这些特性进一步提升了开发体验和用户体验
Vue 的响应式系统
与此同时,Vue 采用的是响应式系统,Vue 3 中的响应式系统通过 Proxy 对象重写,该机制允许 Vue 检测到任何嵌套属性的变化,从而实现更为精准和高效的更新
Vue 的核心目标包括:
简洁的 API 和易于上手:
Vue 重视开发体验,并致力于提供简单且强大的模板语法和计算属性,让开发者快速构建高效的应用
细粒度的更新机制:
Vue 的响应式系统能够精确地追踪依赖变化,保证只有相关的组件会重新渲染,从而提高性能
优化的打包大小和运行性能:
Vue 3 引入 Composition API,促进了代码的组织性,同时也使得 Vue 的核心更轻量,提升了运行时性能
为什么 React 需要 Fiber,而 Vue 不需要?
不同的更新策略和焦点:
React 的 Fiber 架构主要解决的是长时间的、阻塞式更新所带来的性能问题,以及实现异步渲染的能力
而 Vue 通过其响应式系统和细粒度的更新机制,关注的是依赖追踪和高效的组件更新
核心设计理念的差异:
React 通过 JSX 和组件树构建应用,强调组件的状态管理和更新
Vue 则侧重于模板和响应式数据绑定,提供一种更直观的开发方式
这些核心的设计理念导致了它们在技术实现和优化方向上的不同选择
总的来说,React 的 Fiber 架构和 Vue 的响应式系统分别体现了这两个框架针对性能优化和开发体验的不同策略和重点。每种方式都有其适用的场景和优点,而选择使用哪一个往往取决于项目的需求、团队的熟悉度以及个人偏好。
引申
Q5:JSX是什么,它和JS有什么区别
难度:⭐
答案
JSX(JavaScript XML)是 JavaScript 的一个语法扩展,最常用于 React 组件中描述 UI 结构
JSX 使得你可以在 JavaScript 代码中写类似于 HTML 的标记,从而创建 React 元素
虽然 JSX 在视觉上看起来与 HTML 相似,但它在底层完全是 JavaScript
当编译这些 JSX 代码时(通常是使用 Babel 这样的转译器),它们会被转换成 React.createElement 调用
以下是一些主要的区别:
语法形式
JSX 是一种混合的语法,允许 HTML 和 JavaScript 混合编写
而在纯 JavaScript 中,你需要显式地通过 JavaScript 方法来创建和操作 DOM
执行环境
在浏览器中直接运行纯 JS 没有问题,但 JSX 代码需要先经过转译,才能被浏览器理解
表达能力
JSX 提供了一种更加声明式的方式来描述 UI 组件的结构和呈现逻辑,而不是在 JavaScript 中手动地创建和管理 DOM 元素
JSX代码如下:
1 | const element = <h1>Hello, world!</h1>; |
它转换为以下JS代码:
1 | const element = React.createElement('h1', null, 'Hello, world!'); |
Q6:为什么在本地开发时,组件会渲染两次
难度:⭐⭐
答案
React 严格模式会在开发环境中触发一些额外的检查和警告,以帮助开发者发现潜在的问题
具体来说,严格模式会在以下情况下触发组件的额外渲染:
识别副作用
React 会在严格模式下对某些生命周期方法和 Hooks 进行双重调用,以便更容易地发现副作用
例如,
useEffect中的副作用会被调用两次,以确保副作用是幂等的(即多次调用不会产生不同的结果)检测不安全的生命周期方法
严格模式会检测一些不安全的生命周期方法,如
componentWillMount、componentWillReceiveProps和componentWillUpdate,并给出警告确保一致性
通过双重调用构造函数、渲染方法和某些生命周期方法,React 可以确保组件在不同环境下的一致性
引申
如何确认是否是严格模式引起的
你可以检查你的代码是否使用了严格模式
严格模式通常通过 <React.StrictMode> 包裹你的应用根组件来启用,如下所示:
1 | import React from 'react'; |
如何避免双重渲染
严格模式的双重渲染仅在开发环境中启用,并不会影响生产环境
因此,通常不需要担心这种行为在生产环境中会带来性能问题
如果你确实需要在开发过程中避免双重渲染(例如,为了调试某些特定问题),你可以暂时移除 <React.StrictMode> 包裹,但请注意,这只是一个临时解决方案,不建议长期使用,因为严格模式提供了许多有价值的检查和警告
1 | import React from 'react'; |
Q7:虚拟 dom 有什么优点?真实 dom 和虚拟 dom,谁快
难度:⭐⭐⭐⭐
答案
虚拟DOM(Virtual DOM)是一个编程概念,其中UI的表示形式保留在内存中,并与“实际”的DOM(Document Object Model)同步
这个过程称为调和(reconciliation)
虚拟DOM提供几个关键优点:
高效的更新
虚拟DOM可以快速的在内存中重新渲染UI,因为它不立即操作真实的DOM
只有当虚拟DOM和真实DOM之间的差异计算完成后,真实DOM的必要部分才会更新,从而减少了直接操作真实DOM的次数
批量更新和最小化DOM操作
操作真实DOM相比操作JavaScript对象要慢得多
虚拟DOM使React能够批量更新,将多个更改放在一起,然后一次性将它们应用到真实DOM上,从而最小化DOM操作次数
抽象层
虚拟DOM作为一个抽象层,使得开发者不需要直接与DOM交互,简化了编程模型并提高了UI更新的效率和性能
跨平台
虚拟DOM不仅可以工作在浏览器环境,也可以用在其他环境(如服务器端渲染SSR、原生移动应用React Native)上,因为它是独立的
真实DOM与虚拟DOM比较
真实DOM:
直接操作真实DOM会导致浏览器频繁重绘界面和回流,消耗性能较大
DOM操作是破坏性的,简单的更新操作可能会引发整个子树的重新渲染
虚拟DOM:
更新是在JavaScript内存中进行的,消耗较低
React等框架会智能计算出最小的DOM操作次数,仅修改需要更新的部分
所以在多数情况下,虚拟DOM都会比真实DOM更快,因为它减少了昂贵的DOM操作并在必要时才进行批处理更新
但是需要注意的是,在某些简单的操作或者超小的DOM结构的情况下,直接操作真实DOM可能会更快,因为引入虚拟DOM涉及到的差异比对(Diffing)算法和更新计划也有一定代价
总的来说,虚拟DOM并不是在所有情况下都绝对“快过”真实DOM
它的优势在于,对于大型和复杂的应用,它可以通过智能的更新策略大幅度提高效率
真实DOM的优势在于简单场景下的快速响应和直观操作
Q8:什么是合成事件,与原生事件有什么区别
难度:⭐⭐⭐⭐
答案
在 React 中,事件处理机制是通过合成事件(Synthetic Events)实现的
理解合成事件与原生事件之间的区别对开发 React 应用程序非常重要
合成事件(Synthetic Events)
合成事件是 React 实现的一种跨浏览器的事件系统,它封装了浏览器的原生事件,提供了一致的 API
React 使用合成事件来确保在不同浏览器中具有相同的行为
合成事件与原生事件的区别
跨浏览器兼容性:
合成事件
React 通过合成事件提供了一个跨浏览器的事件系统,确保在不同浏览器中具有一致的行为
原生事件
浏览器的原生事件在不同浏览器中可能会有不同的行为和 API
事件委托:
合成事件
React 使用事件委托(Event Delegation)模式,将所有的事件处理器都绑定到根元素上(如
document或root元素)当事件触发时,React 会通过事件冒泡机制找到相应的组件并调用其事件处理器
原生事件
原生事件处理器通常直接绑定到具体的 DOM 元素上
性能优化:
合成事件
由于事件处理器是绑定在根元素上的,React 可以通过事件委托减少内存消耗和提高性能,尤其是在有大量事件处理器的情况下
原生事件
直接绑定在具体 DOM 元素上的事件处理器,可能会在有大量事件处理器时导致性能问题
事件对象:
合成事件
React 提供的事件对象是
SyntheticEvent,它是对原生事件对象的封装SyntheticEvent提供了一致的接口,并且在事件处理后会被回收以提高性能原生事件
浏览器提供的事件对象,接口在不同浏览器中可能会有所不同
示例:合成事件和原生事件
1 | import React from 'react'; |
在这个示例中,当按钮被点击时,handleClick 方法会被调用:
event是一个合成事件对象 (SyntheticEvent)event.nativeEvent是原生事件对象
主要特性
自动清理
合成事件对象会在事件处理函数执行完毕后被清理,以提高性能
这意味着你不能异步访问合成事件对象的属性
如果需要异步访问,可以调用
event.persist()方法1
2
3
4
5
6handleClick = (event) => {
event.persist(); // 防止事件对象被回收
setTimeout(() => {
console.log('SyntheticEvent:', event);
}, 1000);
};一致性
合成事件提供了一致的 API,解决了不同浏览器之间的差异。
总结
- 合成事件 是 React 提供的一种跨浏览器的事件系统,封装了原生事件,提供了一致的 API,并通过事件委托提高性能
- 原生事件 是浏览器提供的事件系统,不同浏览器可能存在差异,事件处理器通常直接绑定在具体的 DOM 元素上
Q9:数据如何在React组件中流动
难度:⭐⭐
答案
React组件通信
react组件通信方式有哪些
组件通信的方式有很多种,可以分为以下几种:
- 父组件向子组件通信
- 子组件向父组件通信
- 兄弟组件通信
- 父组件向后代组件通信
- 无关组件通信
父组件向子组件通信
- props传递,利用React单向数据流的思想,通过props传递
1 | javascript复制代码function Child(props){ |
子组件向父组件通信
- 回调函数
父组件向子组件传递一个函数,通过函数回调,拿到子组件传过来的值
1 | scala复制代码import React from "react" |
- 事件冒泡
点击子组件的button按钮,事件会冒泡到父组件上
1 | ini复制代码const Child = () => { |
- Ref
1 | scala复制代码import React from "react" |
兄弟组件通信
实际上就是通过父组件中转数据的,子组件a传递给父组件,父组件再传递给子组件b
1 | javascript复制代码import React from "react" |
父组件向后代组件通信
Context
1 | import React from "react" |
HOC
Redux
ref,useRef,forwardRef,useImperativeHandle
作者:lyllovelemon
链接:https://juejin.cn/post/7182382408807743548
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Q10:fiber架构
难度:⭐⭐⭐⭐⭐⭐
答案
什么是fiber,fiber解决了什么问题
在React16以前,React更新是通过树的深度优先遍历完成的,遍历是不能中断的,当树的层级深就会产生栈的层级过深,页面渲染速度变慢的问题,为了解决这个问题引入了fiber,React fiber就是虚拟DOM,它是一个链表结构,返回了return、children、siblings,分别代表父fiber,子fiber和兄弟fiber,随时可中断
Fiber是纤程,比线程更精细,表示对渲染线程实现更精细的控制
应用目的
实现增量渲染,增量渲染指的是把一个渲染任务分解为多个渲染任务,而后将其分散到多个帧里。增量渲染是为了实现任务的可中断、可恢复,并按优先级处理任务,从而达到更顺滑的用户体验
Fiber的可中断、可恢复怎么实现的
fiber是协程,是比线程更小的单元,可以被人为中断和恢复,当react更新时间超过1帧时,会产生视觉卡顿的效果,因此我们可以通过fiber把浏览器渲染过程分段执行,每执行一会就让出主线程控制权,执行优先级更高的任务
fiber是一个链表结构,它有三个指针,分别记录了当前节点的下一个兄弟节点,子节点,父节点。当遍历中断时,它是可以恢复的,只需要保留当前节点的索引,就能根据索引找到对应的节点
Fiber更新机制
初始化
- 创建fiberRoot(React根元素)和rootFiber(通过ReactDOM.render或者ReactDOM.createRoot创建出来的)
- 进入beginWork
workInProgress:正在内存中构建的fiber树叫workInProgress fiber,在第一次更新时,所有的更新都发生在workInProgress树,在第一次更新后,workInProgress树上的状态是最新状态,它会替换current树
current:正在视图层渲染的树叫current fiber树
1 | currentFiber.alternate = workInProgressFiber |
- 深度调和子节点,渲染视图
在新建的alternate树上,完成整个子节点的遍历,包括fiber的创建,最后会以workInProgress树最为最新的渲染树,fiberRoot的current指针指向workInProgress使其变成current fiber,完成初始化流程
更新
- 重新创建workInProgress树,复用当前current树上的alternate,作为新的workInProgress
渲染完成后,workInProgress树又变成current树
双缓冲模式
话剧演出中,演员需要切换不同的场景,以一个一小时话剧来说,在舞台中切换场景,时间来不及。一般是准备两个舞台,切换场景从左边舞台到右边舞台演出
在计算机图形领域,通过让图形硬件交替读取两套缓冲数据,可以实现画面的无缝切换,减少视觉的抖动甚至卡顿。
react的current树和workInProgress树使用双缓冲模式,可以减少fiber节点的开销,减少性能损耗
React渲染流程
如图,React用JSX描述页面,JSX经过babel编译为render function,执行后产生VDOM,VDOM不是直接渲染的,会先转换为fiber,再进行渲染。vdom转换为fiber的过程叫reconcile,转换过程会创建DOM,全部转换完成后会一次性commit到DOM,这个过程不是一次性的,而是可打断的,这就是fiber架构的渲染流程
vdom(React Element对象)中只记录了子节点,没有记录兄弟节点,因此渲染不可打断
fiber(fiberNode对象)是一个链表,它记录了父节点、兄弟节点、子节点,因此是可以打断的
Q11:React的设计思想
难度:⭐⭐⭐
答案
组件化
每个组件都符合开放-封闭原则,封闭是针对渲染工作流来说的
指的是组件内部的状态都由自身维护,只处理内部的渲染逻辑
开放是针对组件通信来说的,指的是不同组件可以通过props(单项数据流)进行数据交互
数据驱动视图
UI=f(data)
通过上面这个公式得出,如果要渲染界面,不应该直接操作DOM,而是通过修改数据(state或prop),数据驱动视图更新
虚拟DOM
由浏览器的渲染流水线可知,DOM操作是一个昂贵的操作,很耗性能,因此产生了虚拟DOM。虚拟DOM是对真实DOM的映射,React通过新旧虚拟DOM对比,得到需要更新的部分,实现数据的增量更新
Q12:类组件和函数式组件有何不同
难度:⭐
答案
类组件(Class Components)和函数式组件(Function Components)是 React 中定义组件的两种主要方式
它们各有特点和适用场景
以下是它们的主要不同点:
定义方式
类组件
类组件使用 ES6 类语法,并继承自
React.Component它们需要定义一个
render方法来返回 JSX1
2
3
4
5
6
7
8
9import React, { Component } from 'react';
class MyClassComponent extends Component {
render() {
return <div>Hello from Class Component</div>;
}
}
export default MyClassComponent;函数式组件
函数式组件是 JavaScript 函数,它们直接返回 JSX
1
2
3
4
5
6
7import React from 'react';
const MyFunctionComponent = () => {
return <div>Hello from Function Component</div>;
};
export default MyFunctionComponent;
状态管理
类组件
类组件使用
this.state来管理状态,并通过this.setState更新状态1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class MyClassComponent extends Component {
constructor(props) {
super(props);
this.state = {
count: 0,
};
}
increment = () => {
this.setState({ count: this.state.count + 1 });
};
render() {
return (
<div>
<p>Count: {this.state.count}</p>
<button onClick={this.increment}>Increment</button>
</div>
);
}
}函数式组件
函数式组件使用 React Hooks(如
useState)来管理状态1
2
3
4
5
6
7
8
9
10
11
12import React, { useState } from 'react';
const MyFunctionComponent = () => {
const [count, setCount] = useState(0);
return (
<div>
<p>Count: {count}</p>
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
);
};
生命周期方法
类组件
类组件有一系列生命周期方法,如
componentDidMount、componentDidUpdate和componentWillUnmount,用于在组件的不同阶段执行代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class MyClassComponent extends Component {
componentDidMount() {
console.log('Component mounted');
}
componentDidUpdate(prevProps, prevState) {
console.log('Component updated');
}
componentWillUnmount() {
console.log('Component will unmount');
}
render() {
return <div>Class Component</div>;
}
}函数式组件
函数式组件使用
useEffectHook 来处理副作用,相当于组合了componentDidMount、componentDidUpdate和componentWillUnmount1
2
3
4
5
6
7
8
9
10
11
12
13import React, { useEffect } from 'react';
const MyFunctionComponent = () => {
useEffect(() => {
console.log('Component mounted or updated');
return () => {
console.log('Component will unmount');
};
}, []); // 空数组作为依赖项,表示只在挂载和卸载时执行
return <div>Function Component</div>;
};
性能优化
类组件
类组件可以使用
shouldComponentUpdate方法或PureComponent来优化性能1
2
3
4
5
6
7
8
9
10class MyClassComponent extends Component {
shouldComponentUpdate(nextProps, nextState) {
// 自定义逻辑
return true;
}
render() {
return <div>Class Component</div>;
}
}函数式组件
函数式组件可以使用
React.memo来优化性能1
2
3
4
5import React, { memo } from 'react';
const MyFunctionComponent = memo(() => {
return <div>Function Component</div>;
});
可读性和简洁性
函数式组件通常更简洁、更易读,尤其是在使用 Hooks 后
它们更接近于纯函数的概念,使得代码更容易理解和测试
总结
- 类组件:适合需要使用生命周期方法和复杂状态管理的场景
- 函数式组件:更简洁,推荐用于大多数场景,特别是在引入 Hooks 之后
Q13:mobx和 redux 有什么区别
难度:⭐⭐⭐
答案
设计理念
Redux
单一状态树:Redux 使用单一的全局状态树来管理应用状态,这意味着所有的状态都存储在一个对象中
不可变性:Redux 强调状态的不可变性,每次状态更新都会返回一个新的状态对象,而不是直接修改原有状态
纯函数:Redux 的状态更新逻辑是通过纯函数(reducers)来实现的,这些函数接收当前状态和动作(action),然后返回新的状态
可预测性:由于使用纯函数和不可变状态,Redux 的状态管理非常可预测和可调试
MobX
多状态树:MobX 允许使用多个状态树(observables)来管理应用状态,可以根据需要将状态分散在不同的对象中
可变性:MobX 允许直接修改状态对象,更新状态时不需要返回新的状态对象,状态变化是自动追踪和响应的
响应式编程:MobX 采用响应式编程模型,通过观察(observables)和反应(reactions)来自动追踪和响应状态变化
简洁性:MobX 的 API 和使用方式更简洁,适合快速开发和迭代
使用方式
Redux
- 定义状态和动作:
- 使用
createStore创建全局状态树 - 定义动作类型(action types)和动作创建器(action creators)
- 使用
- 定义 reducer:
- 使用纯函数定义 reducer,根据动作类型返回新的状态
- 连接组件:
- 使用
connect高阶组件将 Redux 状态和动作绑定到 React 组件
- 使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33// actions.js
export const increment = () => ({ type: 'INCREMENT' });
// reducer.js
const initialState = { count: 0 };
const counterReducer = (state = initialState, action) => {
switch (action.type) {
case 'INCREMENT':
return { count: state.count + 1 };
default:
return state;
}
};
// store.js
import { createStore } from 'redux';
import counterReducer from './reducer';
const store = createStore(counterReducer);
// Component.js
import React from 'react';
import { connect } from 'react-redux';
import { increment } from './actions';
const Counter = ({ count, increment }) => (
<div>
<p>{count}</p>
<button onClick={increment}>Increment</button>
</div>
);
const mapStateToProps = state => ({ count: state.count });
export default connect(mapStateToProps, { increment })(Counter);- 定义状态和动作:
MobX
- 定义状态和动作:
- 使用
observable定义状态 - 使用
action定义状态更新逻辑
- 使用
- 观察状态:
- 使用
observer高阶组件将 MobX 状态绑定到 React 组件
- 使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// store.js
import { observable, action } from 'mobx';
class CounterStore {
@observable count = 0;
@action increment = () => {
this.count += 1;
};
}
const counterStore = new CounterStore();
export default counterStore;
// Component.js
import React from 'react';
import { observer } from 'mobx-react';
import counterStore from './store';
const Counter = observer(() => (
<div>
<p>{counterStore.count}</p>
<button onClick={counterStore.increment}>Increment</button>
</div>
));
export default Counter;- 定义状态和动作:
特性对比
- 状态管理方式:
- Redux:单一状态树,不可变状态,纯函数
- MobX:多状态树,可变状态,响应式编程
- 学习曲线:
- Redux:相对较陡,需要理解不可变性、纯函数和中间件等概念
- MobX:相对较平缓,更加直观和简洁
- 生态系统和社区:
- Redux:有一个庞大的生态系统和活跃的社区,提供了丰富的中间件和工具
- MobX:社区和生态系统相对较小,但也有一些有用的工具和扩展
- 可调试性:
- Redux:由于状态不可变和使用纯函数,Redux 的状态变化是可预测的,配合 Redux DevTools 等工具,可以方便地进行状态跟踪和时间旅行调试(time-travel debugging)
- MobX:MobX 的状态变化是响应式的,虽然也有调试工具(如 MobX DevTools),但由于状态是可变的,调试和跟踪状态变化可能没有 Redux 那么直观
- 性能:
- Redux:由于状态变化需要通过纯函数和不可变对象,Redux 在处理大规模状态更新时可能会有性能开销,特别是在深层嵌套的状态结构中
- MobX:MobX 通过响应式编程和细粒度的观察机制,可以高效地追踪和响应状态变化,避免了不必要的重新渲染,性能通常较好
- 代码组织:
- Redux:Redux 通常需要将状态、动作和 reducer 分开组织,代码结构相对清晰,但在大型应用中可能会导致样板代码(boilerplate)较多
- MobX:MobX 的代码组织更灵活,可以将状态和动作集中在一个类中,代码量通常较少,开发体验更加简洁
- 中间件和扩展:
- Redux:Redux 有丰富的中间件(如 redux-thunk、redux-saga)和扩展工具,可以方便地处理异步操作和复杂的状态逻辑
- MobX:MobX 本身不需要中间件来处理异步操作,可以直接在 action 中使用异步函数,扩展性相对简单
- 状态管理方式:
选择指南
- 选择 Redux:如果你的应用需要严格的状态管理、可预测性和强大的调试工具,特别是在团队协作和大型项目中,Redux 是一个不错的选择
- 选择 MobX:如果你更倾向于简洁的代码、快速开发和响应式编程,MobX 可能更适合你,特别是在中小型项目或快速迭代的开发环境中
原理
Q1:简述React的生命周期
难度:⭐⭐⭐
答案
在 React 中,生命周期方法是指在组件的不同阶段(如挂载、更新和卸载)执行的特定方法。对于函数式组件,我们主要依赖于 Hooks 来管理这些生命周期事件。以下是 React 组件的生命周期阶段及其对应的 Hooks。
挂载(Mounting)
当组件首次插入到 DOM 中时,会经历以下阶段:
构造函数(Constructor):
- 仅适用于类组件,用于初始化状态和绑定事件处理函数
getDerivedStateFromProps:- 适用于类组件,用于在渲染前更新状态
render:- 类组件和函数组件都会执行此方法,用于返回要渲染的元素
componentDidMount:- 类组件特有的方法,在组件挂载后立即调用
- 对应的 Hook:
useEffect,可以通过传递空数组[]作为第二个参数来模拟componentDidMount
1
2
3useEffect(() => {
// 组件挂载后的逻辑
}, []);
更新(Updating)
组件的状态或属性发生变化时,会经历以下阶段:
getDerivedStateFromProps:- 类组件特有的方法,用于在渲染前更新状态
shouldComponentUpdate:- 类组件特有的方法,用于控制组件是否需要重新渲染
render:- 类组件和函数组件都会执行此方法,用于返回要渲染的元素
getSnapshotBeforeUpdate:- 类组件特有的方法,用于在更新前获取一些信息
componentDidUpdate:- 类组件特有的方法,在组件更新后立即调用
- 对应的 Hook:
useEffect,可以通过传递依赖数组来模拟componentDidUpdate
1
2
3useEffect(() => {
// 组件更新后的逻辑
}, [依赖项]);
卸载(Unmounting)
组件从 DOM 中移除时,会经历以下阶段:
componentWillUnmount:- 类组件特有的方法,用于在组件卸载前执行清理操作
- 对应的 Hook:
useEffect,可以通过返回一个清理函数来模拟componentWillUnmount
1
2
3
4
5useEffect(() => {
return () => {
// 组件卸载前的清理逻辑
};
}, []);
错误处理(Error Handling)
当组件渲染过程中发生错误时,会经历以下阶段:
componentDidCatch:- 类组件特有的方法,用于捕获错误并处理
- 对应的 Hook:
useErrorBoundary(在一些第三方库中提供)
Q2:并发模式是如何执行的
难度:⭐⭐
解析
并发模式是什么
并发模式是React 18引入的一组新特性,用于使React能够更高效地处理大量更新,并提供更流畅的用户体验
并发模式允许React在不阻塞主线程的情况下执行渲染工作,从而使应用程序能够更好地响应用户交互
答案
React 中的并发,并不是指同一时刻同时在做多件事情
因为 js 本身就是单线程的(同一时间只能执行一件事情),而且还要跟 UI 渲染竞争主线程
若一个很耗时的任务占据了线程,那么后续的执行内容都会被阻塞
为了避免这种情况,React 就利用 fiber 结构和时间切片的机制,将一个大任务分解成多个小任务,然后按照任务的优先级和线程的占用情况,对任务进行调度
执行方式
时间切片(Time Slicing)
React可以将渲染工作分成多个小的任务,并在任务之间进行切换
这使得React可以在处理昂贵的渲染工作时,仍然能够响应用户输入和其他高优先级的任务
例如,React可能会暂停一个低优先级的渲染任务,以便处理一个高优先级的用户输入事件
优先级调度(Priority Scheduling)
React会根据任务的重要性来分配优先级
高优先级的任务(如用户输入)会被优先处理,而低优先级的任务(如数据加载后的渲染)会被延后处理
这确保了用户的交互可以得到及时响应,而不必等待所有渲染工作完成
可中断渲染(Interruptible Rendering)
在并发模式下,React的渲染过程是可中断的
如果有更高优先级的任务需要处理,React可以暂停当前的渲染任务,处理完高优先级任务后再继续未完成的渲染任务
Suspense
Suspense是并发模式中的一个重要特性,它允许组件在等待异步数据时显示备用内容(如加载指示器)当异步数据加载完成后,React会自动更新组件
例如:
1
2
3
4
5
6
7
8
9const MyComponent = React.lazy(() => import('./MyComponent'));
function App() {
return (
<Suspense fallback={<div>Loading...</div>}>
<MyComponent />
</Suspense>
);
}
启用方式
在React 18中,可以通过使用新的createRoot API来启用并发模式:
1 | import React from 'react'; |
Q3:useEffect()的清除机制是什么?在什么时候执行
难度:⭐⭐⭐⭐
答案
useEffect 是 React 中用于在函数组件中执行副作用的 Hook
了解它的清除机制对于管理副作用和避免内存泄漏非常重要
下面是对 useEffect 清除机制的详细解释
useEffect清除机制useEffect接受一个函数作为参数,这个函数可以返回一个清除函数(cleanup function)这个清除函数将在以下几种情况下执行:
组件卸载时
当组件从 DOM 中被移除时,React 会执行清除函数
这有助于清理定时器、取消网络请求或清除任何其他副作用
依赖项变化时
如果
useEffect的依赖项(通过第二个参数传递的数组)发生变化,React 会在执行新的副作用之前先执行清除函数这确保了在副作用重新执行之前,任何之前的副作用都被正确清理
示例:清除定时器
下面是一个使用
useEffect设置和清除定时器的示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import React, { useState, useEffect } from 'react';
function Timer() {
const [count, setCount] = useState(0);
useEffect(() => {
const intervalId = setInterval(() => {
setCount(prevCount => prevCount + 1);
}, 1000);
// 清除函数:在组件卸载或依赖项变化时清除定时器
return () => {
clearInterval(intervalId);
};
}, []); // 空数组表示只在组件挂载和卸载时执行
return (
<div>
<h1>Count: {count}</h1>
</div>
);
}
export default Timer;解释
- 设置副作用:在
useEffect中,我们设置了一个定时器,每秒钟更新一次count状态 - 清除函数:返回的清除函数会在组件卸载时执行,清除定时器以避免内存泄漏
- 依赖项数组:空数组
[]作为第二个参数,表示这个useEffect只在组件挂载和卸载时执行一次
- 设置副作用:在
清除函数执行时机
组件卸载时:当组件从 DOM 中被移除时,清除函数会执行。例如,用户导航到另一个页面或条件渲染导致组件被移除时
依赖项变化时:如果
useEffect的依赖项数组中包含的值发生变化,清除函数会在重新运行副作用之前执行例如:1
2
3
4
5
6useEffect(() => {
console.log('Effect ran');
return () => {
console.log('Cleanup ran');
};
}, [dependency]);每当
dependency变化时,清除函数会先执行,然后useEffect会重新运行
总结
- 清除函数的作用:确保在组件卸载或副作用重新运行之前,清理任何可能导致内存泄漏或不必要行为的副作用
- 执行时机:在组件卸载时或依赖项变化时执行
Q4:多次执行 useState(),会触发多次更新吗
难度:⭐⭐
答案
在 React 中,调用 useState 更新状态会触发组件重新渲染
每次调用 setState 方法(useState 返回的更新函数)都会触发一次重渲染
然而,React 会对多次状态更新进行批处理,以优化性能
多次调用
useState的行为假设你有以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import React, { useState } from 'react';
function Counter() {
const [count, setCount] = useState(0);
const increment = () => {
setCount(count + 1);
setCount(count + 1);
setCount(count + 1);
};
return (
<div>
<p>Count: {count}</p>
<button onClick={increment}>Increment</button>
</div>
);
}
export default Counter;在这个例子中,
increment函数调用了三次setCount你可能期望
count会增加 3,但实际上只会增加 1这是因为在同一个事件处理函数中,React 会对状态更新进行批处理
使用函数式更新
要确保每次调用
setCount都基于最新的状态,你可以使用函数式更新:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import React, { useState } from 'react';
function Counter() {
const [count, setCount] = useState(0);
const increment = () => {
setCount(prevCount => prevCount + 1);
setCount(prevCount => prevCount + 1);
setCount(prevCount => prevCount + 1);
};
return (
<div>
<p>Count: {count}</p>
<button onClick={increment}>Increment</button>
</div>
);
}
export default Counter;在这个例子中,
setCount的参数是一个函数,该函数接收之前的状态值prevCount并返回新的状态值这样,每次调用
setCount都会基于最新的状态值进行更新,因此count将正确增加 3状态更新批处理
React 在事件处理函数中会对状态更新进行批处理,以优化性能
这意味着在同一个事件处理函数中多次调用
setState,React 可能会合并这些更新并只进行一次重渲染例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import React, { useState } from 'react';
function Counter() {
const [count, setCount] = useState(0);
const increment = () => {
setCount(count + 1);
setCount(count + 1);
setCount(count + 1);
console.log(count); // 这里的 count 可能还是旧值
};
return (
<div>
<p>Count: {count}</p>
<button onClick={increment}>Increment</button>
</div>
);
}
export default Counter;在
increment函数内部的console.log(count)可能会输出旧的count值,因为状态更新是异步的,且在事件处理函数结束之前不会立即反映出来总结
多次调用
setState在同一个事件处理函数中多次调用
setState,React 会进行批处理,只触发一次重渲染函数式更新
使用函数式更新可以确保每次状态更新都基于最新的状态值
批处理优化
React 会对状态更新进行批处理,以优化性能
Q5:React 的 diff 过程
难度:⭐⭐⭐⭐⭐
答案
React 的 diff 过程是 React 用来高效更新 DOM 的核心机制之一
这个过程被称为 “reconciliation”(协调),其核心算法被称为 “diffing algorithm”
React 通过 diff 算法比较新旧虚拟 DOM 树(Virtual DOM)之间的差异,并只更新实际需要变更的部分,从而实现高效的更新
Diff 算法的基本原则
React 的 diff 算法主要基于以下三个基本原则:
- 不同类型的元素会产生不同的树:
- 如果两个元素类型不同,React 会销毁旧的树并创建新的树
- 例如,从
<div>变为<span>,React 会移除<div>及其子节点,并创建新的<span>及其子节点
- 相同类型的元素会保留 DOM 节点,仅更新属性:
- 如果两个元素类型相同,React 会保留现有的 DOM 节点,仅更新其属性
- 例如,从
<div className="old">变为<div className="new">,React 只会更新className属性
- 通过 key 属性来识别列表中的元素:
- 对于列表中的元素,React 通过
key属性来识别每个元素 - 如果
key发生变化,React 会认为元素发生了变化,从而销毁旧的并创建新的 - 使用
key可以帮助 React 更高效地更新列表
- 对于列表中的元素,React 通过
Diff 算法的具体步骤
- 比较根节点:
- React 首先比较根节点。如果根节点类型不同,React 会直接替换整个节点树
- 比较子节点:
- 如果根节点类型相同,React 会递归比较子节点
- 如果子节点是文本节点,React 会直接更新文本内容
- 如果子节点是元素节点,React 会比较属性并更新变化的部分
- 列表的比较:
- 对于列表,React 使用
key属性来跟踪每个元素。如果key发生变化,React 会重新创建元素 - React 会尝试最小化 DOM 操作,通过移动、插入和删除节点来更新列表
- 对于列表,React 使用
示例
以下是一个简单的示例,展示了 React 如何通过 diff 算法更新 DOM:
1 | import React, { useState } from 'react'; |
在这个示例中,当点击 Update Items 按钮时,React 会使用 key 属性来比较新旧列表,并只更新变化的部分:
Item 1保持不变Item 2被移除Item 3保持不变,但位置发生变化Item 4被添加
总结
React 的 diff 过程通过以下方式实现高效的 DOM 更新:
- 不同类型的元素会产生不同的树:类型不同直接替换
- 相同类型的元素会保留 DOM 节点,仅更新属性:类型相同只更新变化的属性
- 通过 key 属性来识别列表中的元素:使用
key来高效更新列表
Q6:Redux 遵循的三个原则是什么
难度:⭐⭐
答案
Redux 是一个用于 JavaScript 应用的状态管理库,特别适用于 React 应用
Redux 遵循三个核心原则,这些原则帮助开发者构建可预测、易于调试和维护的应用状态管理系统
单一数据源(Single Source of Truth)
在 Redux 中,整个应用的状态被存储在一个单一的对象树(state tree)中,这个对象树被存储在一个单一的 store 中
这个原则确保了应用的状态是集中管理的,从而使得状态变得更可预测和容易调试
1
2
3
4
5
6
7const initialState = {
user: null,
posts: [],
comments: []
};
const store = createStore(reducer, initialState);状态是只读的(State is Read-Only)
唯一改变应用状态的方法是触发一个 action
Action 是一个描述事件的普通 JavaScript 对象,它们必须具有一个
type属性来指明事件的类型这个原则确保了状态的不可变性,从而使得状态变更可追踪和可调试
1
2
3
4
5
6
7
8
9const action = {
type: 'ADD_POST',
payload: {
id: 1,
title: 'My First Post'
}
};
store.dispatch(action)使用纯函数来执行修改(Changes are Made with Pure Functions)
为了描述 action 如何改变 state 树,你需要编写纯函数
纯函数是指相同的输入总是会产生相同的输出,并且没有副作用
在 Redux 中,这些纯函数被称为 reducers。Reducer 接收当前的 state 和 action,并返回一个新的 state
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15function postsReducer(state = [], action) {
switch (action.type) {
case 'ADD_POST':
return [...state, action.payload];
default:
return state;
}
}
const rootReducer = combineReducers({
posts: postsReducer,
// 其他 reducers
});
const store = createStore(rootReducer);
总结
Redux 的三个核心原则是:
- 单一数据源(Single Source of Truth):整个应用的状态被存储在一个单一的 store 中
- 状态是只读的(State is Read-Only):唯一改变状态的方法是触发一个 action
- 使用纯函数来执行修改(Changes are Made with Pure Functions):reducers 是纯函数,用于描述状态如何根据 action 改变
Q7:你对“单一事实来源”有什么理解
难度:⭐⭐
答案
“单一事实来源”(Single Source of Truth, SSOT)是软件设计中的一个重要原则,特别是在状态管理和数据管理领域
这个原则的核心思想是系统中的所有数据都应该有一个唯一的、权威的来源
这种方法有助于避免数据的不一致性,简化数据管理,并提高系统的可维护性和可预测性
在 Redux 中的应用
在 Redux 中,单一事实来源的原则体现在整个应用的状态被存储在一个单一的对象树(state tree)中,这个对象树被存储在一个唯一的 Redux store 中
以下是这个原则的一些具体好处和实现方式:
好处
数据一致性
当所有状态都集中在一个地方时,数据的一致性更容易维护
你不需要担心不同组件或模块之间的数据不同步问题
可预测性
由于状态集中管理,应用的行为变得更加可预测
你可以通过查看 store 来了解应用的当前状态
易于调试
使用单一的 store,可以很容易地跟踪状态的变化
Redux DevTools 等工具可以帮助开发者查看和回溯状态的变化历史
简化开发
集中管理状态使得应用的结构更加清晰,开发者可以更容易地理解和维护代码
实现方式
在 Redux 中,实现单一事实来源的步骤包括:
创建 Redux Store
使用
createStore函数创建一个 Redux store,这个 store 将包含整个应用的状态1
2
3
4import { createStore } from 'redux';
import rootReducer from './reducers';
const store = createStore(rootReducer);定义 State Tree
应用的状态被定义为一个对象树,可以包含多个属性,每个属性代表应用的一个部分状态
1
2
3
4
5const initialState = {
user: null,
posts: [],
comments: []
};使用 Reducers 管理状态
reducers 是纯函数,用于描述状态如何根据 action 改变
所有的状态变更都通过 reducers 来处理
1
2
3
4
5
6
7
8
9
10
11
12function rootReducer(state = initialState, action) {
switch (action.type) {
case 'ADD_POST':
return {
...state,
posts: [...state.posts, action.payload]
};
// 其他 case
default:
return state;
}
}通过 Actions 修改状态
唯一修改状态的方法是通过 dispatch actions
actions 是描述状态变更的普通 JavaScript 对象
1
2
3
4
5
6
7
8
9const addPostAction = {
type: 'ADD_POST',
payload: {
id: 1,
title: 'My First Post'
}
};
store.dispatch(addPostAction);
总结
“单一事实来源”原则在 Redux 中的应用确保了整个应用的状态是集中管理的,从而使得状态变得更可预测、更一致,并且更容易调试和维护
这种方法不仅适用于 Redux,也可以应用于其他需要管理复杂状态和数据的一些系统和框架中
Q8:Redux 有哪些优点
难度:⭐⭐
答案
单一状态树
Redux 使用单一的状态树(State Tree)来存储整个应用的状态
这意味着所有的状态都集中在一个地方,使得应用的状态管理更加清晰和可预测
可预测的状态管理
Redux 强调状态是不可变的,所有的状态变更必须通过纯函数(Reducers)来处理
这种方式使得状态变更的过程变得透明和可预测,便于调试和测试
易于调试
Redux 提供了强大的调试工具,如 Redux DevTools,可以帮助开发者查看状态的变化、回溯状态历史、时间旅行调试等
这些工具极大地提高了开发和调试的效率
中间件支持
Redux 具有强大的中间件机制,可以在 action 被发送到 reducer 之前进行处理
常见的中间件如 Redux Thunk 和 Redux Saga,可以处理异步操作、日志记录、错误报告等
与 React 的良好集成
Redux 与 React 紧密集成,通过
react-redux库提供的Provider和connect方法,可以方便地将 Redux 的状态和方法注入到 React 组件中,使得组件间的状态共享和通信变得简单社区和生态系统
Redux 拥有庞大的社区和丰富的生态系统,提供了大量的插件和工具,如 Redux Form、Redux Persist、Redux Toolkit 等,帮助开发者更高效地构建应用
可扩展性和可维护性
Redux 的设计模式使得应用的状态管理逻辑高度模块化和可扩展
随着应用的增长,Redux 的结构可以轻松地扩展和维护,而不需要对现有代码进行大规模的重构
一致的数据流
Redux 采用单向数据流的设计,即 action -> reducer -> state 的数据流动方向
这种设计使得数据流动更加简单和直观,减少了双向绑定带来的复杂性和潜在问题
支持服务器渲染
Redux 可以很好地支持服务器端渲染(SSR),通过在服务器端初始化和预填充状态,可以显著提高应用的性能和用户体验
强类型支持
对于使用 TypeScript 的项目,Redux 提供了良好的类型支持,可以显著减少运行时错误,提高开发效率和代码质量
示例代码
以下是一个简单的 Redux 示例,展示了如何创建 store、定义 action 和 reducer,并在 React 组件中使用 Redux 状态:
1 | // actions.js |
Q9:React事件机制
难度:⭐⭐⭐⭐⭐
答案
什么是合成事件
React基于浏览器的事件机制实现了一套自身的事件机制,它符合W3C规范,包括事件触发、事件冒泡、事件捕获、事件合成和事件派发等
React事件的设计动机(作用):
- 在底层磨平不同浏览器的差异,React实现了统一的事件机制,我们不再需要处理浏览器事件机制方面的兼容问题,在上层面向开发者暴露稳定、统一的、与原生事件相同的事件接口
- React把握了事件机制的主动权,实现了对所有事件的中心化管控
- React引入事件池避免垃圾回收,在事件池中获取或释放事件对象,避免频繁的创建和销毁
React事件机制和原生DOM事件流有什么区别
虽然合成事件不是原生DOM事件,但它包含了原生DOM事件的引用,可以通过e.nativeEvent访问
DOM事件流是怎么工作的,一个页面往往会绑定多个事件,页面接收事件的顺序叫事件流
W3C标准事件的传播过程:
- 事件捕获
- 处于目标
- 事件冒泡
常用的事件处理性能优化手段:事件委托
把多个子元素同一类型的监听函数合并到父元素上,通过一个函数监听的行为叫事件委托
我们写的React事件是绑定在DOM上吗,如果不是绑定在哪里
React16的事件绑定在document上, React17以后事件绑定在container上,ReactDOM.render(app,container)
React事件机制总结如下:
事件绑定 事件触发
- React所有的事件绑定在container上(react17以后),而不是绑定在DOM元素上(作用:减少内存开销,所有的事件处理都在container上,其他节点没有绑定事件)
- React自身实现了一套冒泡机制,不能通过return false阻止冒泡
- React通过SytheticEvent实现了事件合成
React实现事件绑定的过程
1.建立合成事件与原生事件的对应关系
registrationNameModule, 它建立了React事件到plugin的映射,它包含React支持的所有事件的类型,用于判断一个组件的prop是否是事件类型
1 | { |
registrationNameDependencies, 这个对象记录了React事件到原生事件的映射
1 | { |
plugins对象, 记录了所有注册的插件列表
1 | plugins = [LegacySimpleEventPlugin, LegacyEnterLeaveEventPlugin, ...] |
为什么针对同一个事件,即使可能存在多次回调,document(container)也只需要注册一次监听
因为React注册到document(container)上的并不是一个某个DOM节点具体的回调逻辑,而是一个统一的事件分发函数dispatchEvent - > 事件委托思想
dispatchEvent是怎么实现事件分发的
事件触发的本质是对dispatchEvent函数的调用
React事件处理为什么要手动绑定this
react组件会被编译为React.createElement,在createElement中,它的this丢失了,并不是由组件实例调用的,因此需要手动绑定this
为什么不能通过return false阻止事件的默认行为
因为React基于浏览器的事件机制实现了一套自己的事件机制,和原生DOM事件不同,它采用了事件委托的思想,通过dispatch统一分发事件处理函数
React怎么阻止事件冒泡
- 阻止合成事件的冒泡用e.stopPropagation()
- 阻止合成事件和最外层document事件冒泡,使用e.nativeEvent.stopImmediatePropogation()
- 阻止合成事件和除了最外层document事件冒泡,通过判断e.target避免
1 | document.body.addEventListener('click',e=>{ |
Q10:React-Router工作原理
难度:⭐⭐⭐⭐
答案
为什么需要前端路由
- 早期:一个页面对应一个路由,路由跳转导致页面刷新,用户体验差
- ajax的出现使得不刷新页面也可以更新页面内容,出现了SPA(单页应用)。SPA不能记住用户操作,只有一个页面对URL做映射,SEO不友好
- 前端路由帮助我们在仅有一个页面时记住用户进行了哪些操作
前端路由解决了什么问题
- 当用户刷新页面,浏览器会根据当前URL对资源进行重定向(发起请求)
- 单页面对服务端来说就是一套资源,怎么做到不同的URL映射不同的视图内容
- 拦截用户的刷新操作,避免不必要的资源请求;感知URL的变化
react-router-dom有哪些组件
HashRouter/BrowserRouter 路由器
Route 路由匹配
Link 链接,在html中是个锚点
NavLink 当前活动链接
Switch 路由跳转
Redirect 路由重定向
1 | <Link to="/home">Home</Link> |
React Router核心能力:跳转
路由负责定义路径和组件的映射关系
导航负责触发路由的改变
路由器根据Route定义的映射关系为新的路径匹配对应的逻辑
BrowserRouter使用的HTML5的history api实现路由跳转
HashRouter使用URL的hash属性控制路由跳转
前端通用路由解决方案
- hash模式
改变URL以#分割的路径字符串,让页面感知路由变化的一种模式,通过hashchange事件触发
- history模式
通过浏览器的history api实现,通过popState事件触发
Q11:React Render方法的原理是什么?什么时候会被触发
难度:⭐⭐⭐
答案
React 的 render 方法是 React 框架的核心概念之一,用于描述组件的 UI 结构
理解 render 方法的原理和触发条件有助于更好地优化和管理 React 应用的性能
以下是对 render 方法的详细解释:
render 方法的原理
在 React 中,每个组件都有一个 render 方法(对于类组件)或一个返回 JSX 的函数(对于函数组件)
这个方法的主要职责是返回一个描述 UI 的 React 元素树
React 使用这些描述来构建和更新实际的 DOM
类组件中的 render 方法
1 | class MyComponent extends React.Component { |
函数组件中的 render 方法
1 | const MyComponent = () => { |
render 方法的触发条件
render 方法会在以下几种情况下被触发:
组件挂载时
当组件第一次被添加到 DOM 中时,
render方法会被调用。这是组件的初始渲染阶段。组件状态(state)更新时
当组件的状态通过
setState或useState更新时,render方法会被调用,以反映状态的变化1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class MyComponent extends React.Component {
constructor(props) {
super(props);
this.state = { count: 0 };
}
increment = () => {
this.setState({ count: this.state.count + 1 });
};
render() {
return (
<div>
<p>Count: {this.state.count}</p>
<button onClick={this.increment}>Increment</button>
</div>
);
}
}组件接收新的 props 时
当父组件传递给子组件的 props 发生变化时,
render方法会被调用,以反映新的 props1
2
3
4
5
6
7
8
9const ParentComponent = () => {
const [value, setValue] = useState('Hello');
return <ChildComponent value={value} />;
};
const ChildComponent = ({ value }) => {
return <div>{value}</div>;
};强制更新时
可以通过调用
forceUpdate方法强制组件重新渲染,但这种做法不常见,应尽量避免1
2
3
4
5
6
7
8
9
10
11
12
13class MyComponent extends React.Component {
forceUpdateComponent = () => {
this.forceUpdate();
};
render() {
return (
<div>
<button onClick={this.forceUpdateComponent}>Force Update</button>
</div>
);
}
}上下文(context)变化时
如果组件使用了上下文(context),当上下文的值发生变化时,
render方法也会被触发1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17const MyContext = React.createContext();
const ParentComponent = () => {
const [value, setValue] = useState('Hello');
return (
<MyContext.Provider value={value}>
<ChildComponent />
</MyContext.Provider>
);
};
const ChildComponent = () => {
const value = useContext(MyContext);
return <div>{value}</div>;
};
Q12:对Redux的理解以及它的工作原理以及怎么使用
难度:⭐⭐⭐
答案
Redux 的理解
Redux 是一个用于 JavaScript 应用的状态管理库,通常与 React 一起使用
它提供了一个集中化的存储来管理应用的状态,使得状态管理变得更加可预测和可维护
Redux 的工作原理
Redux 的核心概念包括以下几个部分:
Store
Redux 应用的整个状态树都存储在一个单一的 store 中
这个 store 是一个对象,包含了应用的所有状态
Action
Action 是一个描述发生了什么的普通 JavaScript 对象
每个 action 都必须有一个
type属性,通常还会包含其他数据Reducer
Reducer 是一个纯函数,接收当前的 state 和一个 action,并返回一个新的 state
Reducer 根据 action 的
type来决定如何更新 stateDispatch
Dispatch 是一个用于发送 action 的方法
通过调用
store.dispatch(action),你可以触发 state 的更新Subscribe
通过
store.subscribe(listener)方法,你可以订阅 store 的更新当 state 发生变化时,订阅的监听器会被调用
Redux 的使用步骤
以下是如何在一个 React 应用中使用 Redux 的基本步骤:
创建 Action
定义 action 类型和 action 创建函数:
1
2
3
4
5
6
7
8
9
10
11// actions.js
export const INCREMENT = 'INCREMENT';
export const DECREMENT = 'DECREMENT';
export const increment = () => ({
type: INCREMENT,
});
export const decrement = () => ({
type: DECREMENT,
});创建 Reducer
定义一个 reducer 函数来处理 state 更新:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// reducers.js
import { INCREMENT, DECREMENT } from './actions';
const initialState = {
count: 0,
};
const counterReducer = (state = initialState, action) => {
switch (action.type) {
case INCREMENT:
return {
...state,
count: state.count + 1,
};
case DECREMENT:
return {
...state,
count: state.count - 1,
};
default:
return state;
}
};
export default counterReducer;创建 Store
使用
createStore函数创建 Redux store:1
2
3
4
5
6
7// store.js
import { createStore } from 'redux';
import counterReducer from './reducers';
const store = createStore(counterReducer);
export default store;提供 Store
使用
Provider组件将 Redux store 提供给 React 应用:1
2
3
4
5
6
7
8
9
10
11
12
13// index.js
import React from 'react';
import ReactDOM from 'react-dom';
import { Provider } from 'react-redux';
import App from './App';
import store from './store';
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById('root')
);连接 React 组件
使用
useSelector和useDispatch钩子在 React 组件中访问 Redux state 和 dispatch actions:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// Counter.js
import React from 'react';
import { useSelector, useDispatch } from 'react-redux';
import { increment, decrement } from './actions';
const Counter = () => {
const count = useSelector((state) => state.count);
const dispatch = useDispatch();
return (
<div>
<p>Count: {count}</p>
<button onClick={() => dispatch(increment())}>Increment</button>
<button onClick={() => dispatch(decrement())}>Decrement</button>
</div>
);
};
export default Counter;使用组件
在应用中使用你的 Redux 连接组件:
1
2
3
4
5
6
7
8
9
10
11
12// App.js
import React from 'react';
import Counter from './Counter';
const App = () => (
<div>
<h1>Redux Counter Example</h1>
<Counter />
</div>
);
export default App;
Q13:jsx转换成真实Dom的过程
难度:⭐⭐
答案
在 React 中,JSX 是一种语法糖,它让你可以在 JavaScript 中编写类似 HTML 的代码
为了在浏览器中渲染这些代码,JSX 需要被转换成真实的 DOM 元素
这个转换过程可以分为以下几个步骤:
JSX 转换为 JavaScript
首先,JSX 会被 Babel(一个 JavaScript 编译器)转换成
React.createElement调用。这一步通常在构建过程中完成。示例
假设有以下 JSX 代码:
1
const element = <h1>Hello, world!</h1>;
Babel 会将其转换为:
1
const element = React.createElement('h1', null, 'Hello, world!');
React.createElement 生成 React 元素
React.createElement是一个函数,用于创建一个 React 元素。React 元素是一个普通的 JavaScript 对象,描述了你想在屏幕上看到的内容。示例
上面的
React.createElement调用会生成以下 React 元素:1
2
3
4
5
6const element = {
type: 'h1',
props: {
children: 'Hello, world!'
}
};React 元素渲染为虚拟 DOM
React 使用这个 React 元素来构建一个虚拟 DOM 树。虚拟 DOM 是一个轻量级的 JavaScript 对象树,描述了真实 DOM 的结构。
示例
虚拟 DOM 树可能看起来像这样:
1
2
3
4
5
6const virtualDOM = {
type: 'h1',
props: {
children: 'Hello, world!'
}
};虚拟 DOM 转换为真实 DOM
React 通过比较虚拟 DOM 和真实 DOM(即“调和”过程),将虚拟 DOM 转换为真实的 DOM 元素,并进行必要的更新。
示例
在初次渲染时,React 会创建一个新的
h1元素,并将其插入到真实的 DOM 中:1
2
3const h1 = document.createElement('h1');
h1.textContent = 'Hello, world!';
document.getElementById('root').appendChild(h1);更新和调和
当组件的状态或属性发生变化时,React 会重新生成新的虚拟 DOM 树,并将其与旧的虚拟 DOM 树进行比较。这个过程称为“调和”。React 会找出需要更新的部分,并只更新这些部分,从而提高性能。
示例
假设状态更新导致文本从“Hello, world!”变为“Hello, React!”:
1
const newElement = <h1>Hello, React!</h1>;
新的虚拟 DOM 树会是:
1
2
3
4
5
6const newVirtualDOM = {
type: 'h1',
props: {
children: 'Hello, React!'
}
};React 会比较新旧虚拟 DOM 树,发现只有文本内容发生了变化,因此只会更新
h1元素的文本内容
总结
- JSX 转换:JSX 被 Babel 转换为
React.createElement调用 - 生成 React 元素:
React.createElement创建一个描述 UI 的 React 元素对象 - 虚拟 DOM:React 使用 React 元素来构建虚拟 DOM 树
- 真实 DOM:React 将虚拟 DOM 转换为真实 DOM,并插入到页面中
- 更新和调和:当状态或属性变化时,React 通过调和过程只更新必要的部分
Q14:React服务端渲染怎么做?原理是什么
难度:⭐⭐⭐⭐
答案
实现 React 服务端渲染的步骤
设置项目
首先,你需要一个基本的 React 项目和一个 Node.js 服务器。你可以使用
create-react-app来创建一个 React 项目,然后进行一些配置来支持 SSR安装必要的依赖
你需要安装一些额外的依赖,如
express和react-dom/server1
npm install express react-dom/server
创建服务器文件
创建一个
server.js文件,用于设置 Express 服务器并处理 SSR1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// server.js
import express from 'express';
import React from 'react';
import ReactDOMServer from 'react-dom/server';
import App from './src/App';
import fs from 'fs';
import path from 'path';
const app = express();
app.use(express.static(path.resolve(__dirname, 'build')));
app.get('*', (req, res) => {
const app = ReactDOMServer.renderToString(<App />);
const indexFile = path.resolve('./build/index.html');
fs.readFile(indexFile, 'utf8', (err, data) => {
if (err) {
console.error('Something went wrong:', err);
return res.status(500).send('Oops, better luck next time!');
}
return res.send(
data.replace('<div id="root"></div>', `<div id="root">${app}</div>`)
);
});
});
app.listen(3000, () => {
console.log('Server is listening on port 3000');
});修改
package.json在
package.json中添加一个脚本来启动服务器:1
2
3
4"scripts": {
"build": "react-scripts build",
"start": "node server.js"
}构建项目并启动服务器
首先构建项目,然后启动服务器:
1
2npm run build
npm start
React 服务端渲染的原理
服务端渲染的基本原理是将 React 组件在服务器端渲染成 HTML 字符串,然后将其发送到客户端
客户端接收到 HTML 内容后,再通过 React 进行“同构”或“挂载”,使得 React 可以接管这些已经渲染好的 HTML 元素,继续处理后续的交互和状态更新
引申
服务端渲染(Server-Side Rendering ,简称SSR),指由服务侧完成页面的 HTML 结构拼接的页面处理技术,发送到浏览器,然后为其绑定状态与事件,成为完全可交互页面的过程
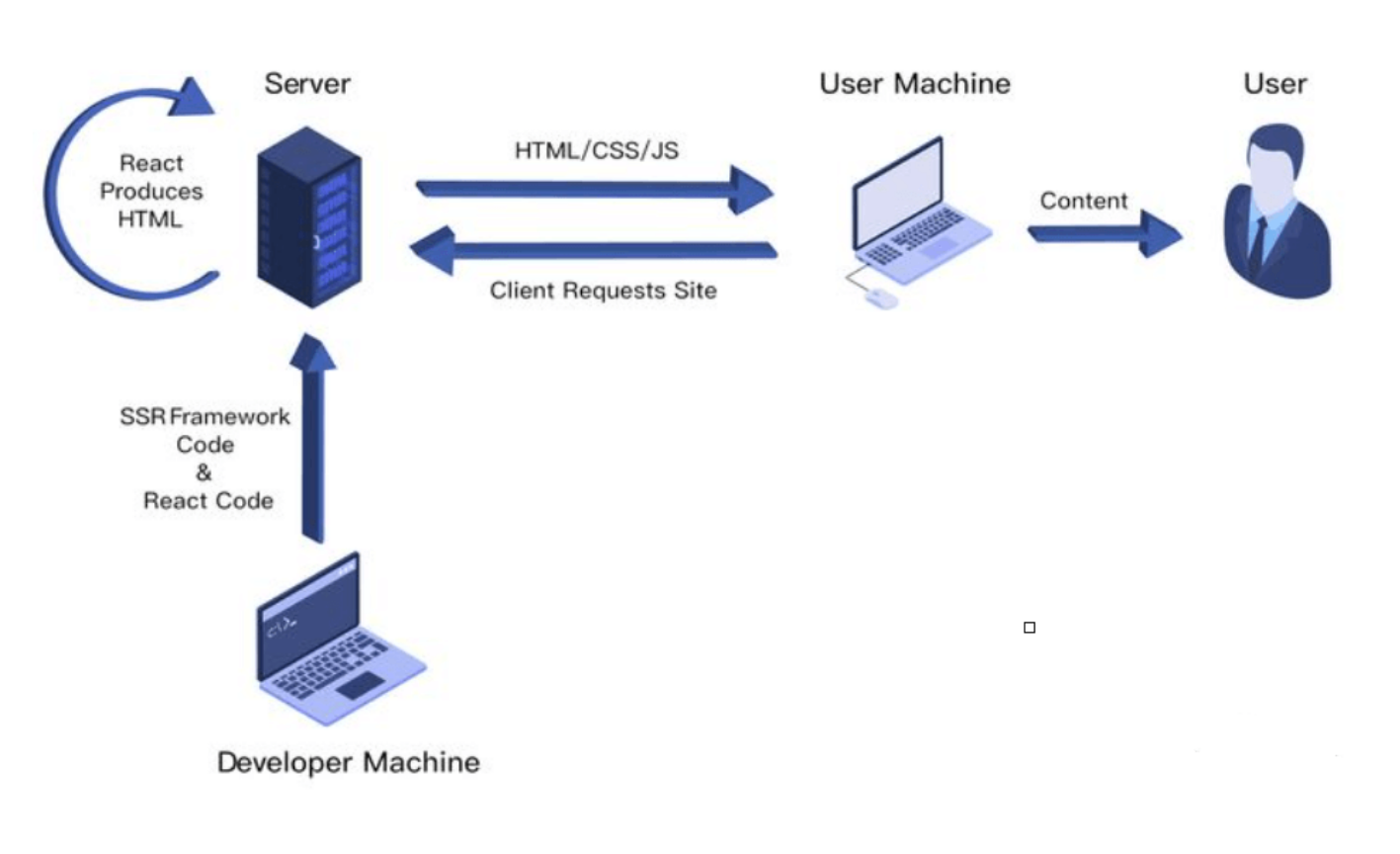
优点
- 更快的首屏渲染:SSR 可以在服务器端生成完整的 HTML 页面,减少了客户端首次渲染的时间
- SEO 友好:搜索引擎可以更容易地抓取和索引服务器端渲染的页面内容
- 更好的用户体验:用户可以更快地看到页面内容,减少了白屏时间
缺点
- 增加了服务器负载:每次请求都需要在服务器端渲染页面,增加了服务器的负载
- 复杂性增加:SSR 需要更多的配置和代码,增加了开发和维护的复杂性
Q15:说说你对 React Hook的闭包陷阱的理解,有哪些解决方案
难度:⭐⭐⭐⭐⭐
答案
React Hooks 中的闭包陷阱(Closure Trap)是一个常见的问题,尤其是在处理状态更新和副作用时
这个问题主要源于 JavaScript 闭包的特性,当你在函数组件中使用 Hooks 时,闭包可能会捕获旧的状态值,从而导致一些意外行为
问题示例
假设你有一个计时器组件,每秒钟更新一次计数器:
1 | import React, { useState, useEffect } from 'react'; |
在这个例子中,setCount(count + 1) 每次都会捕获初始的 count 值(即 0),因为 useEffect 中的函数只在组件挂载时被创建一次。结果是计数器不会正确更新。
解决方案
使用函数式更新
React 提供了一种函数式更新的方式,可以确保你使用的是最新的状态值
你可以通过传递一个函数给
setState来实现:1
2
3
4
5
6
7useEffect(() => {
const interval = setInterval(() => {
setCount(prevCount => prevCount + 1); // 使用最新的 `prevCount`
}, 1000);
return () => clearInterval(interval);
}, []);依赖数组
在
useEffect的依赖数组中添加需要使用的状态或属性,这样每次这些依赖变化时,useEffect都会重新执行:1
2
3
4
5
6
7useEffect(() => {
const interval = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(interval);
}, [count]); // 依赖 `count`但是这种方法在某些情况下可能会导致不必要的重新渲染,因此应谨慎使用
使用
useRef保存最新的状态你可以使用
useRef来保存最新的状态值,并在副作用中引用它:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import React, { useState, useEffect, useRef } from 'react';
function Timer() {
const [count, setCount] = useState(0);
const countRef = useRef(count);
useEffect(() => {
countRef.current = count;
}, [count]);
useEffect(() => {
const interval = setInterval(() => {
setCount(countRef.current + 1); // 使用最新的 `countRef.current`
}, 1000);
return () => clearInterval(interval);
}, []);
return <div>{count}</div>;
}自定义 Hook
你可以创建一个自定义 Hook 来封装计时器逻辑,从而避免重复代码和闭包陷阱:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import React, { useState, useEffect } from 'react';
function useInterval(callback, delay) {
useEffect(() => {
const interval = setInterval(callback, delay);
return () => clearInterval(interval);
}, [callback, delay]);
}
function Timer() {
const [count, setCount] = useState(0);
useInterval(() => {
setCount(prevCount => prevCount + 1);
}, 1000);
return <div>{count}</div>;
}
通过这些方法,你可以有效地避免 React Hooks 中的闭包陷阱,确保你的状态更新和副作用按预期工作
Q16:React Router有几种模式?实现原理是什么
难度:⭐⭐⭐
答案
BrowserRouter概述
BrowserRouter使用 HTML5 的historyAPI 来处理路由这种模式下,URL 看起来是干净的路径(例如
/home,/about),而不会带有#符号实现原理
History API
BrowserRouter利用pushState、replaceState和popstate事件来管理浏览器历史记录和导航URL 结构
直接使用路径名(pathname),例如
/home服务器配置
由于 URL 是干净的路径,服务器需要进行相应的配置,以便在用户直接访问某个路径时,服务器能够正确地返回应用的入口文件(通常是
index.html)这通常涉及到配置服务器进行 URL 重写(URL Rewriting)
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import React from 'react';
import { BrowserRouter as Router, Route, Switch } from 'react-router-dom';
import Home from './Home';
import About from './About';
function App() {
return (
<Router>
<Switch>
<Route path="/home" component={Home} />
<Route path="/about" component={About} />
</Switch>
</Router>
);
}
export default App;Hash Router概述
HashRouter使用 URL 的 hash 部分(即#后面的部分)来管理路由这种模式下,URL 会包含
#符号(例如#/home,#/about)实现原理
Hash Fragment
HashRouter利用浏览器的hashchange事件来检测 URL 变化,并根据 hash 值来导航URL 结构
使用 hash 部分来表示路径,例如
#/home服务器配置:
由于 hash 部分不会被发送到服务器,所以不需要进行额外的服务器配置
这使得
HashRouter在一些静态文件服务器或不支持 URL 重写的环境中非常有用
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import React from 'react';
import { HashRouter as Router, Route, Switch } from 'react-router-dom';
import Home from './Home';
import About from './About';
function App() {
return (
<Router>
<Switch>
<Route path="/home" component={Home} />
<Route path="/about" component={About} />
</Switch>
</Router>
);
}
export default App;
总结
- BrowserRouter:
- 使用 HTML5
historyAPI - URL 是干净的路径
- 需要服务器配置 URL 重写
- 更适合现代单页应用(SPA)
- 使用 HTML5
- HashRouter:
- 使用 URL 的 hash 部分
- URL 包含
#符号 - 不需要服务器配置
- 适合一些静态文件服务器或不支持 URL 重写的环境
组件
Q1:子组件是一个 Portal,发生点击事件能冒泡到父组件吗
难度:⭐⭐⭐
解析
在理解这个问题之前,首先要了解一些基本知识:
React Context:
React 使用 context 来存储组件树的一些信息,比如事件处理程序
当组件使用 Portal 时,Portal 在 React 内部仍然保持在父组件树中,即使在 DOM 上渲染到其他地方
也就是说,Portal 的 context 依然从其父组件继承而来
DOM 事件冒泡:
DOM 中的事件(例如点击事件)通常会从触发事件的元素开始,然后逐步向上冒泡到父元素,直到 document 元素
在这个过程中,事件会按照 DOM 树的层级一层层地向上传递
React 的事件代理:
React 使用事件代理模式将所有事件都代理到顶层(
document或者rootDOM 节点)进行处理这意味着当在子组件中触发一个事件时,无论子组件是否使用了 Portal,React 都会将事件传递到其父组件,然后逐级往上冒泡,直到到达代理事件的顶层
答案
React 的 Portal 通过 React 的 context 和事件冒泡的机制工作
在 React 中,当一个子组件使用 Portal 将其内容渲染到其他 DOM 节点时,尽管在 DOM 结构上子组件不再是父组件的直接子节点,但在 React 的组件树中,子组件仍然是父组件的子节点。这意味着 React 在监听和处理事件时,会沿着组件树的路径(而不是 DOM 树的路径)冒泡事件。因此,子组件中触发的事件仍然会冒泡到父组件。
总结:Portal 在 DOM 结构上将子组件渲染到其他位置,但在 React 的组件树中,它仍然是父组件的子组件。这使得事件可以从子组件沿着组件树冒泡到父组件。
引申
Q2:props 的变动,是否会引起 state hook 中数据的变动
难度:⭐
答案
React 组件的 props 变动,会让组件重新执行,但并不会引起 state 的值的变动
state 值的变动,只能由 setState() 来触发
因此若想在 props 变动时,重置 state 的数据,需要监听 props 的变动,如:
1 | const App = props => { |
Q3:什么是受控组件和非受控组件
难度:⭐⭐⭐
答案
受控
在受控组件中,表单元素的值完全由 React 组件的状态(state)来管理
每当表单元素的值发生变化时,会触发一个事件处理函数来更新状态,从而使表单元素的值与状态保持同步
特点
- 表单元素的值由组件的状态控制
- 每次用户输入都会触发
onChange事件,更新组件的状态
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import React, { useState } from 'react';
import { createRoot } from 'react-dom/client';
function ControlledComponent() {
const [inputValue, setInputValue] = useState('');
const handleChange = (event) => {
setInputValue(event.target.value);
};
const handleSubmit = (event) => {
event.preventDefault();
alert('Submitted value: ' + inputValue);
};
return (
<form onSubmit={handleSubmit}>
<label>
Input:
<input type="text" value={inputValue} onChange={handleChange} />
</label>
<button type="submit">Submit</button>
</form>
);
}
const rootElement = document.getElementById('root');
const root = createRoot(rootElement);
root.render(<ControlledComponent />);非受控
在非受控组件中,表单元素的值由 DOM 自身来管理,而不是通过 React 的状态
你可以使用
ref来访问 DOM 元素,从而获取或设置其值特点
- 表单元素的值由 DOM 自身管理
- 使用
ref来直接访问 DOM 元素
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import React, { useRef } from 'react';
import { createRoot } from 'react-dom/client';
function UncontrolledComponent() {
const inputRef = useRef(null);
const handleSubmit = (event) => {
event.preventDefault();
alert('Submitted value: ' + inputRef.current.value);
};
return (
<form onSubmit={handleSubmit}>
<label>
Input:
<input type="text" ref={inputRef} />
</label>
<button type="submit">Submit</button>
</form>
);
}
const rootElement = document.getElementById('root');
const root = createRoot(rootElement);
root.render(<UncontrolledComponent />);
何时使用受控组件和非受控组件
- 受控组件:
- 适用于需要即时验证或格式化用户输入的场景
- 适合需要与其他组件共享或同步状态的场景
- 更符合 React 的单向数据流理念
- 非受控组件:
- 适用于简单的表单,尤其是当你不需要对输入进行即时验证或格式化时
- 适合需要与第三方库集成的场景,这些库可能直接操作 DOM
关键点总结
- 受控组件:表单元素的值由 React 状态管理,使用
onChange事件处理函数同步状态 - 非受控组件:表单元素的值由 DOM 自身管理,使用
ref直接访问 DOM 元素
Q4:高阶组件是什么
难度:⭐
答案
高阶组件(Higher-Order Component,HOC)是 React 中的一种设计模式,用于复用组件逻辑
HOC 本质上是一个函数,它接收一个组件作为参数,并返回一个新的组件
通过这种方式,你可以在多个组件之间共享逻辑,而不需要重复代码
特点
纯函数:HOC 是纯函数,不会修改传入的组件,而是返回一个新的组件。
逻辑复用:HOC 可以将公共的逻辑抽离出来,在多个组件中复用。
装饰器模式:HOC 类似于装饰器模式,通过增强组件的功能来实现逻辑复用
- 强化 props:这个是 HOC 最常用的用法之一,高阶组件返回的组件,可以劫持上一层传过来的 props,然后混入新的 props,来增强组件的功能。代表作 react-router 中的 withRouter
- 赋能组件:HOC 有一项独特的特性,就是可以给被 HOC 包裹的业务组件,提供一些拓展功能,比如说额外的生命周期,额外的事件,但是这种 HOC,可能需要和业务组件紧密结合。典型案例 react-keepalive-router 中的 keepaliveLifeCycle 就是通过 HOC 方式,给业务组件增加了额外的生命周期
- 控制渲染:劫持渲染是 hoc 一个特性,在 wrapComponent 包装组件中,可以对原来的组件,进行条件渲染,节流渲染,懒加载等功能,后面会详细讲解,典型代表做 react-redux 中 connect 和 dva 中 dynamic 组件懒加载
示例
假设我们有一个需求,需要在多个组件中添加用户认证逻辑。我们可以创建一个 HOC 来实现这个功能
创建 HOC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import React from 'react';
// 高阶组件,添加认证逻辑
function withAuth(WrappedComponent) {
return class extends React.Component {
componentDidMount() {
// 模拟认证逻辑
const isAuthenticated = true; // 这里可以是实际的认证逻辑
if (!isAuthenticated) {
// 如果未认证,重定向到登录页面
window.location.href = '/login';
}
}
render() {
// 如果已认证,渲染传入的组件
return <WrappedComponent {...this.props} />;
}
};
}
export default withAuth;使用 HOC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import React from 'react';
import { createRoot } from 'react-dom/client';
import withAuth from './withAuth';
// 需要认证的组件
function Dashboard() {
return <h1>Dashboard: You are authenticated!</h1>;
}
// 使用 HOC 包装组件
const ProtectedDashboard = withAuth(Dashboard);
const rootElement = document.getElementById('root');
const root = createRoot(rootElement);
root.render(<ProtectedDashboard />);
何时使用高阶组件
逻辑复用:当你需要在多个组件中复用相同的逻辑时,可以考虑使用 HOC
代码分离:HOC 可以帮助你将关注点分离,使组件更专注于自身的逻辑,而将通用逻辑抽离到 HOC 中
增强功能:HOC 可以用于增强组件的功能,例如添加认证、权限控制、数据获取等
注意事项
不要在 render 方法中使用 HOC:避免在组件的
render方法中使用 HOC,因为这会导致每次渲染时都创建新的组件,影响性能静态方法和属性的丢失:HOC 会返回一个新组件,这可能会导致传入组件的静态方法和属性丢失。可以使用
hoist-non-react-statics库来解决这个问题refs 转发:如果需要在 HOC 中访问传入组件的 ref,可以使用 React 的
forwardRefAPI
关键点总结
高阶组件:一个函数,接收一个组件作为参数,并返回一个新的组件
逻辑复用:通过 HOC 可以在多个组件之间共享逻辑,减少重复代码
注意事项:避免在
render方法中使用 HOC,处理静态方法和属性的丢失,以及使用forwardRef转发 refs
Q5:如何实现组件的懒加载
难度:⭐⭐
答案
在React 18及以上版本中,组件的懒加载可以通过React.lazy()函数和Suspense组件实现
懒加载对于提升应用的启动速度和性能非常有帮助,尤其是在加载大型组件或库时
它允许组件仅在需要时才加载,而不是在首次加载应用时加载所有组件
实现步骤
使用
React.lazy导入组件:React.lazy函数允许你定义一个动态加载的组件这个函数接受一个函数作为其参数,这个函数需要动态调用
import()方法,指向你想要懒加载的组件返回值是一个
Promise,它解析为一个default导出的React组件使用
Suspense组件包裹懒加载组件:Suspense组件让你可以在组件树中“等待”某些东西的加载,并且可以指定一个加载指示器(例如加载旋转器),在等待时展示
示例
假设有一个名为SomeComponent的组件,你希望对其进行懒加载:
1 | import React, { Suspense } from 'react'; |
注意事项
Suspense和React.lazy目前仅支持默认导出的组件如果你想要懒加载一个命名导出的组件,你需要在导出组件的文件中创建一个中间组件,将命名导出转换成默认导出
目前
Suspense在服务端渲染(ssr)中只支持加载数据,不支持懒加载组件React团队在未来版本中可能会增加这项支持
在使用路由时(如
react-router-dom),你也可以结合路由懒加载,以实现按路由划分代码,进一步优化应用性能
通过这种方式,你可以显著减少应用的初始加载时间,提升用户体验
Q6:常用组件
难度:⭐⭐⭐
答案
错误边界
React部分组件的错误不应该导致整个应用崩溃,为了解决这个问题,React16引入了错误边界
使用方法:
React组件在内部定义了getDerivedStateFromError或者componentDidCatch,它就是一个错误边界。getDerviedStateFromError和componentDidCatch的区别是前者展示降级UI,后者记录具体的错误信息,它只能用于class组件
1 | import React from "react" |
错误边界无法捕获自身的错误,也无法捕获事件处理、异步代码(setTimeout、requestAnimationFrame)、服务端渲染的错误
Portal
Portal提供了让子组件渲染在除了父组件之外的DOM节点的方式,它接收两个参数,第一个是需要渲染的React元素,第二个是渲染的地方(DOM元素)
1 | ReactDOM.createPortal(child,container) |
用途:弹窗、提示框等
Fragment提供了一种将子列表分组又不产生额外DOM节点的方法
常规的组件数据传递是使用props,当一个嵌套组件向另一个嵌套组件传递数据时,props会被传递很多层,很多不需要用到props的组件也引入了数据,会造成数据来源不清晰,多余的变量定义等问题,Context提供了一种跨层级组件数据传递的方法
1 | const ThemeContext = React.createContext('light') |
Suspense使组件允许在某些操作结束后再进行渲染,比如接口请求,一般与React.lazy一起使用
Transition
Transition是React18引入的一个并发特性,允许操作被中断,避免回到可见内容的Suspense降级方案
Q7:React.Children.map 和 js 的 map 有什么区别
难度:⭐⭐
答案
React.Children.map 和JavaScript的数组map方法都用于遍历集合并对集合中的每一项应用一个函数,但它们之间存在一些关键的区别,特别是在应用场景和行为方面
应用场景的区别
JavaScript的
map方法这是Array原型上的一个方法,用于遍历数组并对数组中的每一项执行给定的函数,最后返回一个新的数组
它是JavaScript数组操作的一部分,可以用于任何数组对象
React.Children.map方法这是React专门为处理
props.children提供的方法props.children
可能是不透明的数据结构,比如Array、null、undefined或单一的React元素React.Children.map方法解决了直接使用JavaScript数组的map方法处理props.children可能遇到的问题,它能够为我们智能处理这些情况
行为差异
对于
null和undefined的处理当
props.children为null或undefined时,React.Children.map会直接返回null或undefined,而不会尝试进行任何遍历,这意味着它在处理空子节点时更加安全相比之下,JavaScript的
map方法在接收到null或undefined作为输入时会抛出异常,因为null和undefined并不是数组,也没有map方法键(key)管理
当在React中处理多个子元素时,每个子元素应该有一个独一无二的“key”属性
React.Children.map
方法在遍历子元素时能够保留这些“key”的唯一性在普通的JavaScript数组中使用
map方法时,开发者需要手动管理这些“key”
Q8:React项目如何捕获错误
难度:⭐⭐⭐
答案
在 React 项目中,捕获和处理错误是确保应用稳定性和用户体验的重要部分
React 提供了多种方式来处理错误,包括错误边界(Error Boundaries)和使用 JavaScript 的 try-catch 语句
以下是一些常见的方法来捕获和处理错误
使用错误边界(Error Boundaries)
错误边界是一个 React 组件,它可以捕获其子组件树中的 JavaScript 错误,并显示一个回退 UI,而不是崩溃整个应用。错误边界只能捕获生命周期方法和构造函数中的错误,不能捕获事件处理函数中的错误。
创建一个错误边界组件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import React from 'react';
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
static getDerivedStateFromError(error) {
// 更新 state 以触发下一次渲染时显示回退 UI
return { hasError: true };
}
componentDidCatch(error, errorInfo) {
// 你可以在这里记录错误信息到日志服务
console.error("Error caught by ErrorBoundary:", error, errorInfo);
}
render() {
if (this.state.hasError) {
// 你可以自定义回退 UI
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
}
export default ErrorBoundary;使用错误边界组件
1
2
3
4
5
6
7
8
9
10
11import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import ErrorBoundary from './ErrorBoundary';
ReactDOM.render(
<ErrorBoundary>
<App />
</ErrorBoundary>,
document.getElementById('root')
);捕获事件处理函数中的错误
错误边界不能捕获事件处理函数中的错误。你需要在事件处理函数中手动使用
try-catch语句。示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23import React from 'react';
class MyComponent extends React.Component {
handleClick = () => {
try {
// 可能会抛出错误的代码
throw new Error('Something went wrong!');
} catch (error) {
console.error('Error caught in event handler:', error);
// 你可以在这里显示错误信息或采取其他措施
}
}
render() {
return (
<button onClick={this.handleClick}>
Click me
</button>
);
}
}
export default MyComponent;捕获异步代码中的错误
对于异步代码,如
async/await,你也需要使用try-catch语句来捕获错误。示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import React from 'react';
class MyComponent extends React.Component {
fetchData = async () => {
try {
let response = await fetch('https://api.example.com/data');
let data = await response.json();
console.log(data);
} catch (error) {
console.error('Error caught in async function:', error);
// 你可以在这里显示错误信息或采取其他措施
}
}
componentDidMount() {
this.fetchData();
}
render() {
return (
<div>
Data will be fetched when component mounts.
</div>
);
}
}
export default MyComponent;使用第三方库
你还可以使用一些第三方库来捕获和处理错误,例如 Sentry 或者 LogRocket,这些库提供了更强大的错误监控和报告功能。
示例(使用 Sentry)
1
npm install @sentry/react @sentry/tracing
1
2
3
4
5
6
7
8
9
10
11
12
13
14import * as Sentry from '@sentry/react';
import { Integrations } from '@sentry/tracing';
Sentry.init({
dsn: 'YOUR_SENTRY_DSN',
integrations: [new Integrations.BrowserTracing()],
tracesSampleRate: 1.0,
});
class App extends React.Component {
// Your app code
}
export default Sentry.withProfiler(App);
总结
- 错误边界:用于捕获组件树中的错误,显示回退 UI
- 事件处理函数中的错误:使用
try-catch语句 - 异步代码中的错误:使用
try-catch语句 - 第三方库:如 Sentry,提供更强大的错误监控和报告功能
Q9:React.memo()和useMemo()的用法是什么有哪些区别
难度:⭐⭐⭐⭐
答案
React.memo()用法
React.memo()是一个高阶组件(Higher-Order Component),用于优化函数组件的性能它通过对比前后两次的 props 来决定是否重新渲染组件,如果 props 没有变化,组件将不会重新渲染
示例
1
2
3
4
5
6
7
8import React from 'react';
const MyComponent = React.memo(({ name }) => {
console.log('Rendering MyComponent');
return <div>Hello, {name}!</div>;
});
export default MyComponent;在这个例子中,如果
MyComponent的nameprop 没有变化,组件将不会重新渲染。用法扩展
可以通过传递自定义的比较函数来进一步控制渲染逻辑:
1
2
3
4
5
6
7
8
9const MyComponent = React.memo(
({ name, age }) => {
console.log('Rendering MyComponent');
return <div>Hello, {name}! You are {age} years old.</div>;
},
(prevProps, nextProps) => {
return prevProps.name === nextProps.name && prevProps.age === nextProps.age;
}
);useMemo()用法
useMemo()是一个 React Hook,用于在组件中缓存计算结果它接受一个创建函数和一个依赖数组,当依赖数组中的值发生变化时,创建函数会重新执行并返回新的值;否则,返回缓存的值
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import React, { useMemo } from 'react';
function MyComponent({ items }) {
const sortedItems = useMemo(() => {
console.log('Sorting items');
return items.sort();
}, [items]);
return (
<ul>
{sortedItems.map(item => (
<li key={item}>{item}</li>
))}
</ul>
);
}
export default MyComponent;在这个例子中,
sortedItems只有在items发生变化时才会重新计算,从而避免不必要的计算
区别
- 用途不同:
React.memo():用于优化整个函数组件的渲染,通过比较 props 来决定是否重新渲染组件useMemo():用于在组件内部缓存计算结果,通过依赖数组来控制何时重新计算
- 使用场景不同:
React.memo():适用于需要防止不必要的重新渲染的函数组件useMemo():适用于需要在渲染过程中进行昂贵计算并希望缓存结果的场景
- 使用方式不同:
React.memo():是一个高阶组件,包裹在函数组件外部useMemo():是一个 Hook,使用在函数组件内部
钩子
Q1:useCallback 和 useMemo 的使用场景
难度:⭐
答案
useCallback 和 useMemo 是 React 的两个钩子(Hooks),它们的目的都是为了优化组件性能,但它们各自的使用场景和目标有所不同
useCallbackuseCallback钩子用于缓存函数,以便在组件重渲染时不会重新创建函数实例,减少不必要的渲染使用场景:
将函数传递给经过优化的子组件,并使用
React.memo或shouldComponentUpdate时,例如:1
2
3
4
5
6const memoizedCallback = useCallback(
() => {
doSomething(a, b);
},
[a, b], // 仅当a或b改变时,才会重新创建这个函数
);在依赖项列表不经常变化,且函数体内有高开销计算时
`useMemouseMemo钩子用于缓存计算得出的值,这意味着你可以告诉React仅在某些依赖项改变时才重新计算该值。使用场景:
高开销计算:当有一个复杂计算且其依赖项不经常变化时,
useMemo可以确保只有在依赖项变化时才重新执行计算1
const memoizedValue = useMemo(() => computeExpensiveValue(a, b), [a, b]);
避免渲染时的不必要的子组件渲染
如果计算得到的值是对象、数组、函数等引用类型,并且这个值被用作子组件的
props,则可以使用useMemo来保持引用的稳定,避免子组件做无用的渲染
注意事项
useCallback和useMemo不保证完全的稳定性,React可能会在内存不足的情况下丢弃缓存值- 过度优化:在没有性能问题的情况下使用这些钩子可能会使你的代码更复杂,不一定总是需要它们
- 缓存机制并不是免费的,它们本身也有开销,因此不应该滥用
Q2:如何实现一个定时器的 hook
难度:⭐
答案
实现一个定时器的 Hook 可以帮助你在 React 函数组件中更方便地使用定时器功能,比如 setTimeout 和 setInterval
下面是一个实现定时器 Hook 的示例,名为 useInterval,它允许你在组件中设置和清除定时器
实现 useInterval Hook
1 | import { useEffect, useRef } from 'react'; |
使用 useInterval Hook
下面是一个使用 useInterval Hook 的示例组件。这个组件每秒更新一次计数器
1 | import React, { useState } from 'react'; |
解释
useRef
我们使用
useRef来保存最新的回调函数,以便在定时器触发时调用最新的回调useEffect (保存回调)
在第一个
useEffect中,我们将最新的回调函数保存到savedCallback中每当回调函数变化时,这个
useEffect会被触发,确保savedCallback始终是最新的useEffect (设置定时器)
第二个
useEffect设置了定时器每当
delay变化时,这个useEffect会被触发如果
delay不为null,我们设置一个新的定时器,并在组件卸载或delay变化时清除之前的定时器
注意事项
清除定时器
在
useEffect中返回一个清除定时器的函数,以确保在组件卸载或delay变化时,定时器被正确清除,避免内存泄漏依赖项
确保在第二个
useEffect中将delay作为依赖项传递,以便在delay变化时重新设置定时器
Q3:useState()的 state 是否可以直接修改?是否可以引起组件渲染
难度:⭐⭐
答案
在 React 中,useState 提供的状态值是不可变的,不能直接修改
直接修改状态值不仅违反了 React 的最佳实践,而且不会触发组件的重新渲染
这是因为 React 依赖于状态的不可变性来检测状态的变化并决定何时重新渲染组件
为什么不能直接修改状态
React 需要知道状态何时发生变化,以便重新渲染组件
如果直接修改状态,React 无法检测到变化,因为它没有办法知道状态的引用是否发生了变化
这会导致组件的 UI 不会更新,甚至可能引起难以调试的错误
示例
假设你有以下代码:
1 | import React, { useState } from 'react'; |
在这个例子中,点击 Increment Directly 按钮不会导致组件重新渲染,因为直接修改 count 不会通知 React 状态已经改变
相反,点击 Increment Properly 按钮会正确更新状态并触发组件重新渲染
正确的状态更新方式
始终使用 setState 函数(useState 返回的更新函数)来更新状态
例如:
1 | const [count, setCount] = useState(0); |
总结
- 不可变性:
useState提供的状态值是不可变的,不能直接修改 - 状态更新:始终使用
setState函数来更新状态 - 组件渲染:直接修改状态不会触发组件重新渲染,正确的状态更新方式会触发重新渲染
Q4:SetState是同步还是异步的
难度:⭐
答案
setState是一个异步方法,但是在setTimeout/setInterval等定时器里逃脱了React对它的掌控,变成了同步方法
实现机制类似于vue的$nextTick和浏览器的事件循环机制,每个setState都会被react加入到任务队列,多次对同一个state使用setState只会返回最后一次的结果,因为它不是立刻就更新,而是先放在队列中,等时机成熟在执行批量更新
React18以后,使用了createRoot api后,所有setState都是异步批量执行的
Q5:React Hooks是什么
难度:⭐
答案
React Hooks 是 React 16.8 引入的一种新特性,它允许你在函数组件中使用状态和其他 React 特性,而不需要编写类组件
Hooks 提供了一种更简洁、更直观的方式来管理组件的状态和副作用
以下是一些常用的 React Hooks:
useStateuseState是一个 Hook,用于在函数组件中添加状态管理1
2
3
4
5
6
7
8
9
10
11
12import React, { useState } from 'react';
const Counter = () => {
const [count, setCount] = useState(0);
return (
<div>
<p>Count: {count}</p>
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
);
};useEffectuseEffect是一个 Hook,用于在函数组件中处理副作用,例如数据获取、订阅或手动更改 DOM它相当于类组件中的
componentDidMount、componentDidUpdate和componentWillUnmount的组合1
2
3
4
5
6
7
8
9
10
11
12
13import React, { useEffect } from 'react';
const Example = () => {
useEffect(() => {
console.log('Component mounted or updated');
return () => {
console.log('Component will unmount');
};
}, []); // 空数组作为依赖项,表示只在挂载和卸载时执行
return <div>Example Component</div>;
};useContextuseContext是一个 Hook,用于在函数组件中使用上下文它允许你在组件树中传递数据,而不需要显式地通过每一层组件传递 props
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import React, { useContext } from 'react';
const MyContext = React.createContext();
const MyComponent = () => {
const value = useContext(MyContext);
return <div>{value}</div>;
};
const App = () => (
<MyContext.Provider value="Hello, World!">
<MyComponent />
</MyContext.Provider>
);useReduceruseReducer是一个 Hook,用于在函数组件中管理复杂的状态逻辑它类似于 Redux 的 reducer 概念
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26import React, { useReducer } from 'react';
const initialState = { count: 0 };
function reducer(state, action) {
switch (action.type) {
case 'increment':
return { count: state.count + 1 };
case 'decrement':
return { count: state.count - 1 };
default:
throw new Error();
}
}
const Counter = () => {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<div>
<p>Count: {state.count}</p>
<button onClick={() => dispatch({ type: 'increment' })}>Increment</button>
<button onClick={() => dispatch({ type: 'decrement' })}>Decrement</button>
</div>
);
};useRefuseRef是一个 Hook,用于在函数组件中访问 DOM 元素或保存一个可变值,该值在整个组件的生命周期内保持不变1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import React, { useRef } from 'react';
const TextInput = () => {
const inputEl = useRef(null);
const focusInput = () => {
inputEl.current.focus();
};
return (
<div>
<input ref={inputEl} type="text" />
<button onClick={focusInput}>Focus the input</button>
</div>
);
};useMemouseMemo是一个 Hook,用于在函数组件中优化性能,通过记住计算结果,只有在依赖项变化时才重新计算1
2
3
4
5
6
7
8
9
10import React, { useMemo } from 'react';
const ExpensiveCalculation = ({ num }) => {
const result = useMemo(() => {
console.log('Calculating...');
return num * 2;
}, [num]);
return <div>Result: {result}</div>;
};`useCallback``
`useCallback是一个 Hook,用于在函数组件中优化性能,通过记住函数定义,只有在依赖项变化时才重新创建函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import React, { useState, useCallback } from 'react';
const Button = React.memo(({ onClick }) => {
console.log('Button rendered');
return <button onClick={onClick}>Click me</button>;
});
const App = () => {
const [count, setCount] = useState(0);
// 使用 useCallback 记住这个回调函数,只有当 count 改变时才重新创建
const handleClick = useCallback(() => {
setCount(count + 1);
}, [count]);
return (
<div>
<p>Count: {count}</p>
<Button onClick={handleClick} />
</div>
);
};
export default App;
Q6:React)事件和原生事件的执行顺序
难度:⭐⭐⭐
答案
在 React 中,事件处理机制与原生 DOM 事件处理机制有一些不同
这些差异包括事件代理(event delegation)和合成事件(synthetic events)
理解 React 事件和原生事件的执行顺序有助于更好地调试和优化 React 应用
React 事件系统
React 使用合成事件(Synthetic Events)来处理事件
这种机制在所有浏览器中提供一致的事件行为,并且通过事件代理将所有事件处理程序附加到组件树的根节点上,从而提高性能
执行顺序
当一个事件被触发时,React 事件和原生事件的执行顺序如下:
原生事件捕获阶段
在事件捕获阶段,事件从文档的根节点向下传播到目标元素
这时,任何在捕获阶段注册的原生事件处理程序都会被执行
React 事件捕获阶段
React 事件处理程序也可以在捕获阶段执行
如果你在 React 中使用捕获事件处理程序(通过在事件名后加
Capture例如onClickCapture),这些处理程序会在原生事件捕获阶段之后执行原生事件目标阶段
在事件目标阶段,事件在目标元素上被触发,任何在目标元素上注册的原生事件处理程序会被执行
React 事件目标阶段
React 的合成事件处理程序会在目标阶段执行
这些处理程序会在原生事件处理程序之后执行
原生事件冒泡阶段
在事件冒泡阶段,事件从目标元素向上传播到文档的根节点
这时,任何在冒泡阶段注册的原生事件处理程序都会被执行
React 事件冒泡阶段
React 事件处理程序也可以在冒泡阶段执行
如果你在 React 中使用常规事件处理程序(例如
onClick),这些处理程序会在原生事件冒泡阶段之后执行
示例代码
以下是一个示例,用于演示 React 事件和原生事件的执行顺序:
1 | import React, { useEffect } from 'react'; |
执行顺序解释
- Native Capture:原生事件捕获阶段
- React Capture:React 事件捕获阶段
- Native Bubble:原生事件目标和冒泡阶段
- React Bubble:React 事件目标和冒泡阶段
Q7:为什么不能在循环、条件或嵌套函数中调用Hooks
难度:⭐⭐⭐
答案
在 React 中,Hooks 是一套强大的 API,用于在函数组件中管理状态和副作用
然而,React 对 Hooks 的使用有一些严格的规则,其中之一就是不能在循环、条件语句或嵌套函数中调用 Hooks
这是因为 React 需要确保 Hooks 的调用顺序在每次渲染时都是一致的
原因
React 依赖于 Hooks 调用顺序来正确地管理状态和副作用
如果你在循环、条件语句或嵌套函数中调用 Hooks,Hooks 的调用顺序可能会在不同的渲染周期中发生变化,从而导致不可预测的行为和错误
具体原因如下:
Hooks 的调用顺序
React 使用一个内部的调用栈来跟踪每个组件中的 Hooks 调用
如果 Hooks 的调用顺序在不同的渲染周期中发生变化,React 就无法正确地将状态和副作用与相应的组件实例对应起来
状态和副作用的管理
Hooks 是用来管理组件的状态和副作用的
如果它们的调用顺序不一致,React 可能会错误地更新状态或执行副作用,从而导致应用程序的行为异常
代码示例
以下是一些违反规则的示例:
在循环中调用 Hooks
1 | // ❌ 错误的用法 |
在条件语句中调用 Hooks
1 | // ❌ 错误的用法 |
在嵌套函数中调用 Hooks
1 | // ❌ 错误的用法 |
正确的用法
Hooks 应该在函数组件的顶层调用,确保每次渲染时它们的调用顺序都是一致的
1 | // ✅ 正确的用法 |
React 的官方规则
React 官方提供了两条使用 Hooks 的规则:
- 只在最顶层调用 Hooks:不要在循环、条件语句或嵌套函数中调用 Hooks
- 只在 React 函数组件和自定义 Hooks 中调用 Hooks:不要在普通的 JavaScript 函数中调用 Hooks
Q8:useRef/ref/forwardsRef 的区别是什么
难度:⭐⭐
答案
useRefuseRef是一个 React Hook,主要用于在函数组件中创建一个可变的引用对象它可以用来持久化某个值,或者引用一个 DOM 元素
用途
- 持久化某个值,不会因为组件的重新渲染而丢失
- 直接访问 DOM 元素
示例
1
2
3
4
5
6
7
8
9
10
11
12import React, { useRef, useEffect } from 'react';
function MyComponent() {
const inputRef = useRef(null);
useEffect(() => {
// 组件挂载后,自动聚焦到 input 元素
inputRef.current.focus();
}, []);
return <input ref={inputRef} />;
}refref是一个属性,用于在类组件中创建对 DOM 元素或 React 组件实例的引用它可以通过
React.createRef创建用途
- 在类组件中引用 DOM 元素或组件实例
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import React, { Component } from 'react';
class MyComponent extends Component {
constructor(props) {
super(props);
this.inputRef = React.createRef();
}
componentDidMount() {
// 组件挂载后,自动聚焦到 input 元素
this.inputRef.current.focus();
}
render() {
return <input ref={this.inputRef} />;
}
}forwardsRefforwardRef是一个高阶组件,用于将 ref 转发到子组件它允许父组件通过 ref 直接访问子组件的 DOM 元素或组件实例
用途
- 在高阶组件中转发 ref
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import React, { forwardRef } from 'react';
// 创建一个可以接收 ref 的子组件
const MyInput = forwardRef((props, ref) => (
<input ref={ref} {...props} />
));
function ParentComponent() {
const inputRef = React.createRef();
useEffect(() => {
// 组件挂载后,自动聚焦到 input 元素
inputRef.current.focus();
}, []);
return <MyInput ref={inputRef} />;
}
总结
useRef: 用于在函数组件中创建一个可变的引用对象,主要用于持久化某个值或引用 DOM 元素ref: 用于在类组件中创建对 DOM 元素或组件实例的引用,通过React.createRef创建forwardRef: 用于将 ref 转发到子组件,允许父组件通过 ref 直接访问子组件的 DOM 元素或组件实例
Q9:useEffect 的第二个参数,传空数组和传依赖数组有什么区别
难度:⭐
答案
传空数组 (
[])当你将一个空数组作为
useEffect的第二个参数时,意味着这个副作用只会在组件挂载(即第一次渲染)和卸载时执行一次它类似于类组件中的
componentDidMount和componentWillUnmount生命周期方法示例
1
2
3
4
5
6
7
8
9
10
11
12
13import React, { useEffect } from 'react';
function MyComponent() {
useEffect(() => {
console.log('Component mounted');
return () => {
console.log('Component will unmount');
};
}, []);
return <div>MyComponent</div>;
}解释
- 挂载时:
console.log('Component mounted')会在组件挂载时执行 - 卸载时: 返回的清理函数
console.log('Component will unmount')会在组件卸载时执行
- 挂载时:
传依赖数组(如
[dependency1, dependency2])当你将一个包含依赖项的数组作为
useEffect的第二个参数时,意味着这个副作用会在组件挂载以及依赖项发生变化时执行每次依赖项发生变化时,副作用都会重新执行
示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import React, { useEffect, useState } from 'react';
function MyComponent() {
const [count, setCount] = useState(0);
useEffect(() => {
console.log('Effect executed because count changed');
return () => {
console.log('Cleanup executed because count changed');
};
}, [count]);
return (
<div>
<p>Count: {count}</p>
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
);
}解释
- 挂载时:
console.log('Effect executed because count changed')会在组件挂载时执行 - 依赖项变化时: 当
count发生变化时,副作用会重新执行 - 清理副作用: 返回的清理函数
console.log('Cleanup executed because count changed')会在组件卸载或依赖项变化之前执行
- 挂载时:
总结
- 传空数组 (
[]):- 副作用只会在组件挂载和卸载时执行一次
- 类似于类组件中的
componentDidMount和componentWillUnmount
- 传依赖数组(如
[dependency1, dependency2]):- 副作用会在组件挂载时执行,并且在任意一个依赖项发生变化时重新执行
- 类似于类组件中的
componentDidUpdate,同时也会在组件卸载时执行清理函数
Q10:实现-个 useTimeout Hook
难度:⭐⭐⭐
答案
useTimeout 是可以在函数式组件中,处理 setTimeout 计时器函数
解决了什么问题?
如果直接在函数式组件中使用 setTimeout ,会遇到以下问题:
- 多次调用setTimeout
1 | function App() { |
- hooks 的闭包缺陷
1 | function App() { |
useTimeout 实现
1 | function useTimeout(callback, delay) { |
如何使用
1 | // callback 回调函数, delay 延迟时间 |
性能优化
Q1:React 中为什么不直接使用requestldleCallback
难度:⭐⭐⭐⭐
答案
requestIdleCallback 是一个允许开发者在主线程空闲时运行低优先级函数的 Web API
一致性问题
由于
requestIdleCallback的执行时机依赖于浏览器的空闲周期,这会导致在不同浏览器和设备上有不一致的行为React 旨在提供一个一致且可预测的性能表现,以确保开发者能够构建跨平台的、具有一致体验的应用
这种不确定性是 React 选择不直接采用
requestIdleCallback的一个主要原因
实时性问题
React 的核心之一是能够快速响应用户输入并立即更新 UI
requestIdleCallback执行的时间可能不足以满足这种实时性需求,尤其是在高优先级的更新(如动画或响应用户输入)应该立即发生时这种潜在的延迟对于保持良好的用户体验来说是不可接受的。
调度器控制
React 内部实现了一个任务调度器,负责根据任务的优先级来管理和调度它们的执行
这样的设计允许 React 在保持用户界面响应性的同时进行高效的背景更新
直接使用
requestIdleCallback可能会干扰这种精细调度策略,从而引起不可预测的行为为了克服这些挑战,React 引入了 Scheduler 模块
Scheduler 模块使得 React 能够以更细粒度的方式安排任务的执行,确保关键任务(如用户输入响应)得到及时处理,同时也使得可以在浏览器空闲时执行低优先级任务
这种方法提供了更高的控制度和一致性,同时也保留了在合适的时机执行后台任务的能力
总结
综上所述,虽然
requestIdleCallback提供了在浏览器空闲时执行任务的有趣机制,但对于 React 这样需要高度一致性、响应实时性,并且具有细粒度调度控制要求的库而言,直接使用它并不符合需求React 通过实现 Scheduler 模块,提供了一个更加适配其内部机制的解决方案,既保证了应用的响应性和用户体验,也实现了背景任务的有效管理。这种设计选择反映了 React 团队对于性能优化和用户体验优先级的综合考虑
Q2:React 中为什么要使用 Hook
难度:⭐⭐⭐
答案
简化代码结构
Hooks 使得函数组件可以处理状态和副作用,从而避免了类组件中复杂的生命周期方法和
this绑定问题函数组件通常更简洁、更直观
逻辑复用
在类组件中,共享状态逻辑通常需要使用高阶组件(HOC)或 Render Props,这可能导致组件层级嵌套过深
Hooks 允许你通过自定义 Hook 来提取状态逻辑,从而实现更好的逻辑复用和代码组织
更好的代码可读性和可维护性
使用 Hooks 可以将组件的逻辑按功能分块,而不是按生命周期方法分块
这使得代码更容易理解和维护
例如,一个自定义 Hook 可以封装数据获取逻辑,而另一个自定义 Hook 可以封装表单处理逻辑
避免类组件的复杂性
类组件中的
this关键字使用容易出错,特别是对于初学者Hooks 通过函数组件完全避免了
this的使用,从而减少了错误和困惑更细粒度的状态控制
Hooks 提供了更细粒度的状态控制
你可以使用多个
useState或useReducerHook 来管理不同的状态变量,而不是将所有状态都放在一个大的 state 对象中更好的性能优化
Hooks 使得 React 的性能优化(如
useMemo和useCallback)更加直观和易于使用,从而减少不必要的重新渲染和性能开销常用的 Hooks
useState: 用于在函数组件中添加状态useEffect: 用于在函数组件中处理副作用(如数据获取、订阅等)useContext: 用于在函数组件中使用 React 的上下文useReducer: 用于在函数组件中管理复杂的状态逻辑useMemo和useCallback: 用于性能优化,避免不必要的计算和函数创建useRef: 用于访问 DOM 元素或保持不需要重新渲染的变量
Q3:key 的作用是什么
难度:⭐
答案
在React中,key 是一个特殊的属性,你应该在映射组件的列表时包含它
它的主要作用是帮助React识别哪些项已经改变、添加或者删除的
正确使用key可以带来一些重要的性能优化
作用
唯一性
React使用
key来匹配组件树上的组件实例与重新渲染过程中的新元素key`需要是唯一的,以便于区分同一父元素下的不同子元素
重用与重排序
当组件的列表顺序改变时,
key可以帮助React确定哪些组件可以保留并重新排序,而不是销毁重新创建这可以提高效率和性能
状态保留
如果组件状态需要跨渲染周期保持一致,
key用于追踪哪些组件是保持不变的这意味着如果组件的
key没有改变,它的状态会保持不变避免不必要的重新渲染
当列表变动时,如果没有
key,React将重新渲染整个列表,增加开销合适的
key确保组件能够正确地被复用,只有变动的部分被重新渲染
错误用法
使用索引作为
key在一些情况下,使用数组索引作为
key是可以的,比如静态列表或者不进行排序和修改的列表但是如果项的顺序可能会改变,这会导致性能问题甚至错误的行为,因为React依赖于
key来识别子元素随机生成的
key如果
key是在每次渲染时生成的(如使用Math.random()),这将导致组件的不必要重渲染,因为React会认为key在每次渲染时都是新的
在选择key的时候,最好使用能够代表列表项唯一性的字符串,这通常是来自数据本身的ID或者哈希值
这样做不仅保证了性能,也保证了组件状态的稳定
Q4:基于 React 框架的特点,可以有哪些优化措施
难度:⭐⭐⭐⭐
答案
React是一个用于构建用户界面的JavaScript库,特别强调了组件化开发和声明式编程
虽然React自身提供了高效的渲染策略,但在实际开发中我们仍然可以通过多种方式来进一步优化应用性能和用户体验
以下是一些常用的React应用优化措施:
使用
React.memo优化组件渲染React.memo是一个高阶组件,它仅在组件的props发生变化时才重新渲染组件,从而避免了不必要的渲染懒加载组件
对于大型应用,采用代码拆分和组件的懒加载非常有效
可以使用
React.lazy和Suspense来按需加载组件,减少初始加载时间使用
shouldComponentUpdate或React.PureComponent在类组件中,通过实现
shouldComponentUpdate方法,你可以控制组件是否需要更新React.PureComponent提供了一个浅比较的shouldComponentUpdate实现方式,如果你的组件渲染完全由props和state决定,这是一个很好的选择键值(Key)优化
在渲染列表时,合理使用
key可以帮助React识别哪些元素改变了、添加或删除这可以提高渲染效率,减少重新渲染的开销
合理使用状态(State)和副作用(Effect)
- 避免在一个组件内部过度使用状态,尤其是当数据可以通过props传递时
- 使用
useEffect的依赖数组来精确控制副作用的执行时机,避免不必要的执行
使用Context提供者和消费者模式优化
使用React的Context API可以避免
props的层层传递,但是若不当使用也可能造成不必要的渲染合理使用
useContext钩子或Context.Consumer可以优化这一点避免匿名函数和对象字面量作为props
组件的props中使用匿名函数和对象字面量会在每次父组件渲染时创建新的实例,这可能导致不必要的子组件渲染
可以通过使用useCallback和useMemo来避免这种情况
动态导入库和代码
利用
import()函数可以实现对代码和库的动态导入,进一步减少应用的初始大小。服务端渲染(SSR)
通过服务端渲染可以提高首屏加载速度,提升SEO性能。React提供了库如Next.js支持服务端渲染
使用Webpack优化构建
使用Webpack进行代码拆分,提取公共库,压缩代码,利用缓存策略等技术可以减少应用的加载时间
Q5:react-router 和 react-router-dom 的有什么区别
难度:⭐
答案
React Router 是一个用于在 React 应用中实现路由功能的库,而 react-router-dom 是其专门为浏览器环境设计的一个子包
为了更好地理解它们之间的区别,下面是详细的解释:
React Router
react-router 是 React Router 库的核心包,包含了实现路由功能的核心逻辑
这个包可以在各种环境中使用,如浏览器、React Native、Electron 等
它提供了基础的路由组件和 API,例如:
RouterRouteSwitchRedirectLinkNavLink
React Router DOM
react-router-dom 是专门为浏览器环境设计的一个包,它依赖于 react-router,并在其基础上添加了一些特定于浏览器的功能和组件
这个包提供了浏览器特有的路由组件和 API,例如:
BrowserRouterHashRouterLinkNavLinkPromptRedirect
主要区别
- 使用环境:
react-router是核心库,可以在多种环境中使用react-router-dom是专门为浏览器环境设计的
- 组件:
react-router提供了基本的路由组件,如Route、Switch等react-router-dom在react-router的基础上,提供了浏览器特有的组件,如BrowserRouter、HashRouter等
- 依赖关系:
react-router-dom依赖于react-router,并扩展了其功能
示例
以下是一个使用 react-router-dom 的简单示例:
1 | import React from 'react'; |
在这个示例中:
BrowserRouter是react-router-dom提供的一个组件,用于在浏览器环境中实现路由Link是react-router-dom提供的用于导航的组件Route和Switch是react-router提供的基础路由组件
总结
react-router是 React Router 的核心包,包含了基础的路由功能,可以在多种环境中使用react-router-dom是专门为浏览器环境设计的包,扩展了react-router的功能,提供了浏览器特有的路由组件
 wechat
wechat alipay
alipay










