
《手写JavaScript 面试题》
实现目标功能
Q1:二分查找
难度:⭐⭐
解析
在 JavaScript 中,可以使用几种不同的方法来实现二分查找算法,具体取决于个人的编程偏好和问题的特性。以下是几种常见的实现方式:
迭代法
使用 while 循环来不断缩小搜索范围,直到找到目标值或确定目标值不存在于数组中。
递归法
通过递归调用来实现二分查找算法,将数组分割成更小的部分
无论使用哪种方法,二分查找的核心思想都是将搜索范围一分为二,通过比较中间元素和目标值的大小关系来决定继续搜索的方向,从而达到快速查找的目的
答案
1 | function binarySearch(arr, target) { |
引申
递归法
1 | function binarySearchRecursive(arr, target, left = 0, right = arr.length - 1) { |
Q2:怎么预防用户连续快速点击,造成数据多次提交?
难度:⭐⭐
答案
为了防止用户连续快速点击造成数据多次提交,你可以考虑以下几种方法:
防抖(Debouncing):
防抖是一种控制函数调用频率的技术,通过延迟执行函数来确保在一定时间内只触发一次。当用户连续快速点击时,只有最后一次点击会触发实际的操作。
在前端中,你可以使用 JavaScript 中的
setTimeout和 clearTimeout来实现防抖。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13let timer;
function debounce(fn, delay) {
clearTimeout(timer);
timer = setTimeout(() => {
fn();
}, delay);
}
// 在点击事件中使用防抖
button.addEventListener('click', () => {
debounce(submitData, 1000); // 1000 毫秒内只会触发一次 submitData 函数
});
禁用按钮:
在用户点击后,禁用提交按钮,防止连续点击。可以在提交后添加一个 loading 状态,完成后再启用按钮。
例如:
1
2
3
4button.addEventListener('click', () => {
button.disabled = true;
submitData();
});
点击间隔判断:
记录上一次点击的时间戳,在点击时判断与上一次点击的时间间隔,只有在时间间隔足够长时才执行实际的提交操作。
例如:
1
2
3
4
5
6
7
8
9let lastClickTime = 0;
button.addEventListener('click', () => {
const currentTime = new Date().getTime();
if (currentTime - lastClickTime > 1000) { // 限定间隔为 1000 毫秒
submitData();
lastClickTime = currentTime;
}
});
Q3:实现温度转换函数,让华氏度跟摄氏度可以互相转换,结果保留两位小数
难度:⭐
解析
公式:(摄氏度 * 9/5) + 32
答案
1 | // 将摄氏度转换为华氏度 |
Q4:使用原生js给一个按钮绑定两个onclick事件
难度:⭐
答案
1 |
|
Q5:给某个资源的链接,如 https://www.baidu.com/index.html请实现一个方法,获取该资源的后缀,如 html
难度:⭐
答案
切割
1
2
3
4
5
6
7
8
9
10
11
12function getFileExtension(url) {
// 获取最后一个斜杠后面的内容
const filename = url.split('/').pop();
// 获取最后一个点后面的内容作为后缀
const extension = filename.split('.').pop();
return extension;
}
// 示例用法
const url = "https://www.baidu.com/index.html";
const fileExtension = getFileExtension(url);
console.log(fileExtension); // 输出 "html"这个方法首先通过拆分URL来获取文件名,然后再从文件名中获取后缀。需要注意的是,这个方法假设文件名中只有一个点作为后缀名的分隔符,并且后缀名在点后面。如果URL中包含查询参数或片段标识符,可能需要进行额外的处理以避免错误。
正则
1
2
3
4
5
6
7
8
9
10
11
12
13
14function getFileExtension(url) {
// 使用正则表达式匹配最后一个点后面的内容作为后缀
const extension = url.match(/\.([^.]+)$/);
if (extension) {
return extension[1];
} else {
return ""; // 如果没有后缀,则返回空字符串
}
}
// 示例用法
const url = "https://www.baidu.com/index.html";
const fileExtension = getFileExtension(url);
console.log(fileExtension); // 输出 "html"这个方法使用正则表达式
\.[^.]+$来匹配最后一个点后面的内容作为后缀,然后返回匹配到的结果。如果没有找到后缀,则返回空字符串。与之前的方法相比,这种方法更加灵活,可以处理更多可能的情况。获取索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16function getFileExtension(url) {
// 找到最后一个点的索引
const lastDotIndex = url.lastIndexOf('.');
if (lastDotIndex !== -1) {
// 切片并获取后缀
const extension = url.slice(lastDotIndex + 1);
return extension;
} else {
return ""; // 如果没有后缀,则返回空字符串
}
}
// 示例用法
const url = "https://www.baidu.com/index.html";
const fileExtension = getFileExtension(url);
console.log(fileExtension); // 输出 "html"这个方法首先使用
lastIndexOf()方法找到最后一个点的索引,然后通过切片获取后缀。如果没有找到后缀,则返回空字符串。这种方法比较简洁,并且与正则表达式相比,可能具有更好的性能。
Q6:一个滚动公告组件,如何在鼠标滑入时停止播放,在鼠标离开时继续等待滑入时的剩余等待时间后播放?
难度:⭐
答案
要实现这样的滚动公告组件,你可以使用 JavaScript 来控制滑入和滑出事件,并结合定时器来暂停和恢复播放。下面是一个基本的实现示例:
HTML:
1 | <div id="announcement">这是滚动公告内容</div> |
JavaScript:
1 | // 获取公告元素 |
这个代码片段首先定义了一个滚动公告的容器,然后设置了滚动的速度和内容。接着定义了一个函数 scrollAnnouncement() 来执行滚动公告的动作,并设置了一个定时器来控制滚动的频率。在鼠标移入和移出事件中,暂停和恢复滚动的操作通过设置一个自定义属性 data-paused 来实现。当鼠标移入时,先暂停滚动,然后等待剩余的滚动时间后再继续滚动。
Q7:怎么把十进制的 0.2 转换成二进制?
难度:⭐
答案
1 | function decimalToBinary(decimal, precision) { |
这个函数 decimalToBinary() 接受两个参数:要转换的十进制数和转换后二进制的精度(即位数)。然后通过循环将小数不断乘以 2,并根据结果的整数部分确定二进制的相应位数。最终返回的二进制字符串即为所需的结果。
引申
乘以 2 取整法和除以 2 取余法
- 乘以 2 取整法:
- 优点:
- 不涉及除法运算,乘法运算通常比除法运算更高效,因此在某些情况下可能更快。
- 适用于不需要精确表示小数的情况,例如计算机中的浮点数表示。
- 计算方式:
- 首先将十进制数乘以 2,然后取整部分作为二进制的下一位数。
- 如果乘以 2 的结果大于等于 1,则记录为 1,并将结果减去 1;否则记录为 0。
- 然后将结果乘以 2,继续重复以上步骤,直到得到所需的位数或者小数部分为 0。
- 适用场景:
- 在计算机程序中,特别是涉及到浮点数转换为二进制表示时,可能更常用乘以 2 取整法。
- 优点:
- 除以 2 取余法:
- 优点:
- 更直观易懂,与人们对十进制到二进制的转换过程更为熟悉。
- 对于需要精确表示小数的情况,除以 2 取余法可以提供更准确的结果。
- 计算方式:
- 首先将十进制数除以 2,然后取余数作为二进制的下一位数。
- 将商作为新的要除以 2 的十进制数。
- 继续重复以上步骤,直到得到的商为 0。
- 适用场景:
- 在需要精确表示小数的情况下,例如数学计算、金融领域等,除以 2 取余法可能更为适用。
- 优点:
Q8:请对以下数组,根据born”的值降序排列
难度:⭐
1 | const singers = [ |
答案
使用 sort() 方法和箭头函数:
1 | singers.sort((a, b) => b.born - a.born); |
引申
使用 reduce() 方法:
1
2
3
4
5
6
7
8
9const sortedSingers = singers.reduce((acc, cur) => {
const insertIndex = acc.findIndex(item => item.born < cur.born);
if (insertIndex === -1) {
acc.push(cur);
} else {
acc.splice(insertIndex, 0, cur);
}
return acc;
}, []);这种方法使用了 reduce() 方法遍历原数组,然后根据 born 属性的值将元素插入到新数组的适当位置,最终得到的新数组就是按 born 属性的值降序排列的数组。
使用 Array.prototype.concat() 和 for…of 循环:
1
2
3
4
5
6
7
8
9
10
11
12
13
14const sortedSingers = [];
for (const singer of singers) {
let inserted = false;
for (let i = 0; i < sortedSingers.length; i++) {
if (singer.born > sortedSingers[i].born) {
sortedSingers.splice(i, 0, singer);
inserted = true;
break;
}
}
if (!inserted) {
sortedSingers.push(singer);
}
}这种方法使用了 for…of 循环遍历原数组,然后根据 born 属性的值将元素插入到新数组的适当位置,最终得到的新数组就是按 born 属性的值降序排列的数组。
使用 Array.prototype.unshift() 方法:
1
2
3
4
5
6const sortedSingers = [];
singers.forEach(singer => {
let i = 0;
while (sortedSingers[i] && singer.born < sortedSingers[i].born) i++;
sortedSingers.splice(i, 0, singer);
});这种方法使用了 forEach() 方法遍历原数组,然后根据 born 属性的值将元素插入到新数组的适当位置,最终得到的新数组就是按 born 属性的值降序排列的数组。
使用 Array.prototype.push() 和 Array.prototype.pop() 方法:
1
2
3
4
5
6
7
8
9const sortedSingers = [];
singers.forEach(singer => {
const index = sortedSingers.findIndex(item => item.born < singer.born);
if (index === -1) {
sortedSingers.push(singer);
} else {
sortedSingers.splice(index, 0, singer);
}
});这种方法使用了 forEach() 方法遍历原数组,然后根据 born 属性的值将元素插入到新数组的适当位置,最终得到的新数组就是按 born 属性的值降序排列的数组。
使用 Array.prototype.push() 和 Math.max() 方法:
1
2
3
4
5const sortedSingers = [];
singers.forEach(singer => {
const index = Math.max(...sortedSingers.map(item => item.born < singer.born ? sortedSingers.indexOf(item) : -1));
sortedSingers.splice(index + 1, 0, singer);
});这种方法使用了 forEach() 方法遍历原数组,然后根据 born 属性的值将元素插入到新数组的适当位置,最终得到的新数组就是按 born 属性的值降序排列的数组。
使用 Array.prototype.reduceRight() 方法:
1
2
3
4
5
6
7
8
9const sortedSingers = singers.reduceRight((acc, cur) => {
const insertIndex = acc.findIndex(item => item.born < cur.born);
if (insertIndex === -1) {
acc.push(cur);
} else {
acc.splice(insertIndex, 0, cur);
}
return acc;
}, []);这种方法使用了 reduceRight() 方法遍历原数组,然后根据 born 属性的值将元素插入到新数组的适当位置,最终得到的新数组就是按 born 属性的值降序排列的数组。
Q9 :遍历一个任意长度的list中的元素并依次创建异步任务如何获取所有任务的执行结果?
难度:⭐
答案
1 | function asyncTask(item) { |
引申
Promise.all() 和 Promise.allSettled() 是两种不同的 Promise 组合方法,它们之间有一些关键的区别:
- Promise.all():
- 当所有 Promise 都成功解决时,返回一个包含所有 Promise 结果的数组。
- 如果其中任何一个 Promise 被拒绝(rejected),则立即将返回的 Promise 对象标记为拒绝,并且会传递第一个被拒绝的 Promise 的拒因(rejection reason)。
- 如果有一个 Promise 被拒绝,那么其他 Promise 的执行依然会继续,但
Promise.all()返回的 Promise 对象将被标记为拒绝,无法获取其他 Promise 的结果。
- Promise.allSettled():
- 等待所有 Promise 执行完成,不管是成功还是失败,都会返回一个包含所有 Promise 执行结果的数组。
- 返回的 Promise 对象状态总是成功的,不会因为其中的某个 Promise 被拒绝而导致整个组合 Promise 被拒绝。
- 返回的数组中的每个元素都是一个对象,代表对应的 Promise 执行结果,包括状态(fulfilled 或 rejected)和对应的值或拒因。
简而言之,Promise.all() 等待所有 Promise 解决,如果有一个被拒绝则整个组合 Promise 被拒绝;而 Promise.allSettled() 等待所有 Promise 执行完成,无论成功或失败,返回的 Promise 总是成功的,并提供每个 Promise 的执行结果。
Q10:怎么把函数中的 arguments 转成数组?
难度:⭐
答案
Array.from() 方法:
- 使用
Array.from()方法可以将类数组对象转换为数组。 - 实现原理:
Array.from()方法从一个类数组或可迭代对象中创建一个新的数组实例。它会遍历类数组对象的每个元素,并将其添加到新数组中。
1
2
3
4
5
6
7function myFunction() {
const argsArray = Array.from(arguments);
return argsArray;
}
const result = myFunction(1, 2, 3);
console.log(result); // 输出: [1, 2, 3]- 使用
Array.prototype.slice.call() 方法:
- 使用
Array.prototype.slice.call()方法通过调用数组的slice()方法,将一个类数组对象转换为数组。 - 实现原理:
slice()方法可以接受两个参数,第一个参数是开始截取的索引,第二个参数是结束截取的索引。如果省略第二个参数,则从开始索引截取到数组末尾。因为我们没有传入任何参数,所以它会将整个类数组对象转换为数组。
1
2
3
4
5
6
7function myFunction() {
const argsArray = Array.prototype.slice.call(arguments);
return argsArray;
}
const result = myFunction(1, 2, 3);
console.log(result); // 输出: [1, 2, 3]- 使用
扩展运算符
...:- 使用扩展运算符
...可以将一个可迭代对象展开为多个元素,并创建一个包含所有参数的数组。 - 实现原理:扩展运算符
...可以将一个可迭代对象展开为多个元素。在这种情况下,arguments对象是一个可迭代对象,因此使用...arguments可以将其展开为多个参数。
1
2
3
4
5
6
7function myFunction() {
const argsArray = [...arguments];
return argsArray;
}
const result = myFunction(1, 2, 3);
console.log(result); // 输出: [1, 2, 3]- 使用扩展运算符
引申
在 JavaScript 中,arguments 是一个特殊的对象,用于在函数内部访问传递给函数的参数列表。它类似于数组,但并不是一个真正的数组,而是一个类数组对象(Array-like Object)。arguments 对象包含了所有传递给函数的参数,可以通过索引来访问每个参数。
arguments 对象有以下特点:
- 类数组对象:
arguments对象类似于数组,但不是一个真正的数组,因为它没有数组的方法和属性。 - 自动创建:
arguments对象在函数内部自动创建,无需显式声明或定义。 - 包含所有参数:
arguments对象包含了所有传递给函数的参数,包括函数定义时声明的参数以及调用函数时传递的参数。 - 索引访问:可以通过索引来访问
arguments对象中的每个参数,索引从 0 开始。 - length 属性:
arguments对象具有length属性,表示传递给函数的参数数量。
使用 arguments 对象可以使函数更加灵活,因为它允许函数接受任意数量的参数,而不需要提前定义函数参数的个数。然而,由于 arguments 对象不是一个真正的数组,因此不能直接使用数组的方法,例如 push() 和 pop()。 若要在 arguments 对象上使用数组方法,需要先将其转换为真正的数组。
数组和类数组之间的主要区别:
| 特点 | 数组(Array) | 类数组对象(Array-like Object) |
|---|---|---|
| 数据类型 | 存储任意类型的数据,可以是基本类型和对象等 | 只能存储元素,通常是单一类型的 |
| 长度(Length)属性 | 有长度属性 length | 通常没有 length 属性,除非明确添加 |
| 可迭代性(Iterable) | 可以使用迭代器方法(如 forEach, map) | 通常不能直接使用数组方法,但可以通过其他方式进行遍历,如 for...of 或 Array.from() |
| 方法和属性 | 拥有数组方法和属性,如 push, pop, slice | 通常没有数组方法和属性 |
总的来说,数组是 JavaScript 中的一种特殊对象,拥有一系列方法和属性,可以轻松地操作其元素。而类数组对象通常只能存储元素,缺乏数组的方法和属性,但有时可以通过一些技巧或转换方法来模拟数组的行为。
Q11:写一个repeat 方法,实现字符串的复制拼接
难度:⭐
答案
String.prototype.repeat() 方法
1
2
3function repeatString(str, n) {
return str.repeat(n);
}Array.prototype.fill() 方法
1
2
3function repeatString(str, n) {
return new Array(n).fill(str).join('');
}Array.prototype.join() 方法
1
2
3function repeatString(str, n) {
return new Array(n + 1).join(str);
}Array.prototype.map() 方法
1
2
3function repeatString(str, n) {
return Array.from({ length: n }, () => str).join('');
}循环
1
2
3
4
5
6
7function repeatString(str, n) {
let result = '';
for (let i = 0; i < n; i++) {
result += str;
}
return result;
}String.prototype.padStart() 方法
1
2
3function repeatString(str, n) {
return str.padStart(str.length * n, str);
}while 循环
1
2
3
4
5
6
7
8function repeatString(str, n) {
let result = '';
while (n > 0) {
result += str;
n--;
}
return result;
}递归
1
2
3
4function repeatString(str, n) {
if (n === 1) return str;
return str + repeatString(str, n - 1);
}reduce 方法
1
2
3function repeatString(str, n) {
return Array.from({ length: n }).reduce((acc) => acc + str, '');
}Polyfill 方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33if (!String.prototype.repeat) {
String.prototype.repeat = function(count) {
'use strict';
if (this == null)
throw new TypeError('can\'t convert ' + this + ' to object');
var str = '' + this;
// To convert string to integer.
count = +count;
// Check NaN
if (count != count)
count = 0;
if (count < 0)
throw new RangeError('repeat count must be non-negative');
if (count == Infinity)
throw new RangeError('repeat count must be less than infinity');
count = Math.floor(count);
if (str.length == 0 || count == 0)
return '';
// Ensuring count is a 31-bit integer allows us to heavily optimize the
// main part. But anyway, most current (August 2014) browsers can't handle
// strings 1 << 28 chars or longer, so:
if (str.length * count >= 1 << 28)
throw new RangeError('repeat count must not overflow maximum string size');
var maxCount = str.length * count;
count = Math.floor(Math.log(count) / Math.log(2));
while (count) {
str += str;
count--;
}
str += str.substring(0, maxCount - str.length);
return str;
}
}
引申
- String.prototype.repeat() 方法:
- API:
String.prototype.repeat(count) - 参数:
count,一个非负整数,表示要重复字符串的次数。 - 返回值:返回一个新的字符串,该字符串包含指定次数的原始字符串拼接在一起的结果。
- API:
- Array.prototype.fill() 方法:
- API:
Array.prototype.fill(value, start, end) - 参数:
value,要填充到数组中的值;start,填充的起始索引(可选,默认为0);end,填充的结束索引(可选,默认为数组末尾)。 - 返回值:修改后的数组。
- API:
- Array.prototype.join() 方法:
- API:
Array.prototype.join(separator) - 参数:
separator,一个可选的字符串,用作分隔符,将数组中的每个元素连接在一起。如果省略,则默认使用逗号作为分隔符。 - 返回值:返回一个由数组元素组成的字符串,每个元素之间由分隔符分隔。
- API:
- Array.prototype.map() 方法:
- API:
Array.prototype.map(callback, thisArg) - 参数:
callback,一个用于处理数组元素的函数,该函数接收三个参数:当前值(currentValue)、当前索引(index)、原数组(array);thisArg,可选参数,用作执行回调时的 this 值。 - 返回值:返回一个新数组,数组中的每个元素都是回调函数的结果。
- API:
- String.prototype.padStart() 方法:
- API:
String.prototype.padStart(targetLength, padString) - 参数:
targetLength,目标字符串的长度;padString,一个可选的填充字符串,默认为空格。 - 返回值:返回一个新的字符串,该字符串由原始字符串重复填充至目标长度后返回。
- API:
- Polyfill 方法:
- 这是一个用于解决在不支持
String.prototype.repeat()方法的环境中提供兼容性的方法。 - 它检查是否存在
String.prototype.repeat()方法,如果不存在则定义一个 Polyfill 方法,否则不做任何操作。 - 该 Polyfill 方法实现了重复字符串的功能,与原生的
String.prototype.repeat()方法功能相同。
- 这是一个用于解决在不支持
Q12:使用is生成1-10000的数组
难度:⭐
答案
1 | const arr = Array.from({ length: 10000 }, (_, index) => index + 1); |
这段代码将创建一个长度为 10000 的数组,并使用箭头函数来填充数组的每个元素,使其从 1 到 10000。
Q13:移动端的点击事件的有延迟,时间是多久,为什么会有?怎么解决这个延时?
难度:⭐⭐
答案
移动端点击事件的延迟通常称为”点击延迟”(Click Delay),在某些移动设备和浏览器中会存在这个问题。这种延迟的主要原因是浏览器为了等待可能的双击事件(double tap),以便在用户进行双击时执行相应的操作。
这个点击延迟的时间通常在 300 毫秒左右,具体时间可能因浏览器和设备而异。
解决这个延时的常见方法包括:
使用
touchstart事件touchstart事件触发的速度更快,可以替代click事件但需要注意的是,
touchstart事件与click事件有一些区别,如在移动设备上长按屏幕时不会触发click事件,但会触发touchstart事件使用 CSS 属性
touch-action: none通过在元素上设置
touch-action: noneCSS 属性来禁用浏览器的默认行为,从而避免点击延迟这个方法可能会影响到页面的默认滚动行为,需要根据具体情况来决定是否使用
使用第三方库或框架
一些 JavaScript 库或框架(如 FastClick、TapJS 等)专门用于解决移动端点击延迟的问题
这些库通常会在内部优化事件处理逻辑,以提供更快的响应速度
meta 标签设置
可以使用
<meta>标签中的viewport属性来控制页面的缩放行为,通过设置user-scalable=no来禁止用户缩放页面,可以减少点击延迟例如:
1
<meta name="viewport" content="width=device-width, initial-scale=1.0, user-scalable=no">
需要注意的是,禁止用户缩放页面可能会影响用户体验,因此需要谨慎使用
优化页面性能
优化页面的性能和加载速度,减少资源的请求和加载时间,可以间接地减少点击延迟
特别是减少 JavaScript 和 CSS 文件的大小和数量,以及优化图片资源的加载方式
Q14:如何判断当前脚本运行在浏览器还是 node 环境中?
难度:⭐⭐
答案
1 | if (typeof window !== 'undefined') { |
引申
在 JavaScript 中,可以通过检查全局对象来判断当前脚本是在浏览器环境还是 Node.js 环境中运行。在浏览器环境中,全局对象是 window,而在 Node.js 环境中,全局对象是 global
Q15:前端路由’a ->b->c`这样前进,也可以返回c->b->a,用什么数据结构来存比较高效
难度:⭐⭐
解析
1 | class Router { |
在这个例子中,navigate方法用于模拟用户导航到新页面的行为,back方法和forward方法分别用于后退和前进。使用栈结构允许我们保持一个清晰的历史记录,并且能够以逆序访问这些记录,这正是我们在浏览器历史中所期望的行为。
答案
- 前进栈(Forward Stack): 当用户从一个页面导航到另一个页面时,将当前页面推入前进栈。
- 后退栈(Back Stack): 当用户点击后退时,将当前页面推入后退栈,并从前进栈中弹出顶部页面来显示。
- 前进: 当用户点击前进按钮时,将当前页面推入后退栈,并从前进栈中弹出顶部页面来显示。
引申
在计算机科学中,管理这种前进和后退(前进和后退导航)的一种有效方法是使用两个栈(堆栈)——一个用于前进历史,另一个用于后退历史。这种方法在许多浏览器的历史功能的实现中被采用
Q16:怎么预防用户快速连续点击,造成数据多次提交
难度:⭐⭐
答案
为了防止重复提交,前端一般会在第一次提交的结果返回前,将提交按钮禁用
禁用按钮:
在提交操作后立即禁用按钮,防止用户再次点击,直到操作完成或过一段时间后重新启用按钮。
示例代码:
1
2
3
4
5
6
7const button = document.querySelector('#submitButton');
button.addEventListener('click', () => {
button.disabled = true;
submitData()
.then(() => button.disabled = false)
.catch((error) => button.disabled = false);
});
节流(Throttle)或防抖(Debounce):
使用节流或防抖函数控制点击事件的频率,限制在特定时间内只允许触发一次。
示例代码(防抖):
1
2
3
4
5
6
7
8
9const debounce = (fn, delay) => {
let timeoutId;
return function (...args) {
clearTimeout(timeoutId);
timeoutId = setTimeout(() => fn.apply(this, args), delay);
};
};
const submitDataDebounced = debounce(submitData, 3000);
button.addEventListener('click', submitDataDebounced);
状态管理:
使用状态管理追踪提交的状态,如果某次提交尚未完成,则拒绝新的提交。
示例代码:
1
2
3
4
5
6
7
8let isSubmitting = false;
button.addEventListener('click', () => {
if (isSubmitting) return;
isSubmitting = true;
submitData()
.then(() => isSubmitting = false)
.catch(() => isSubmitting = false);
});
全屏遮罩:
显示一个全屏遮罩元素阻止用户在关键操作期间与页面交互。
示例代码:
1
2
3
4
5
6
7
8
9
10
11const mask = document.createElement('div');
mask.style = 'position: fixed; top: 0; left: 0; width: 100%; height: 100%; background-color: rgba(0, 0, 0, 0.5); z-index: 1000; display: none;';
document.body.appendChild(mask);
const showMask = () => mask.style.display = 'block';
const hideMask = () => mask.style.display = 'none';
button.addEventListener('click', () => {
showMask();
submitData()
.then(() => hideMask())
.catch(() => hideMask());
});
Q17:实现以下转换,合并连续的数字
难度:⭐⭐
1 | [1,2,3,4,6,7,9,13,15]=>['1->4','6->7','9','13','15'] |
解析
mergeConsecutiveNumbers 函数的思路是将输入数组中的连续数字范围合并成字符串形式,然后返回这些合并后的字符串列表。具体的思路如下:
- 参数验证:
- 首先,函数会验证输入是否为非空数组,以避免空数组或非数组的输入导致的潜在错误
- 如果输入不是数组或者数组为空,则函数直接返回空数组
- 初始化:
- 初始化一个结果数组
result,用于存储最终的合并结果 - 定义变量
start和end,表示当前连续数字范围的开始和结束。初始值均为输入数组的第一个元素
- 初始化一个结果数组
- 帮助函数:
- 定义一个名为
addRangeToResult的帮助函数,用于将连续数字范围添加到结果数组result中 - 如果开始和结束是相同的,则表示这是一个单独的数字;否则表示这是一个连续的数字范围
- 定义一个名为
- 遍历输入数组:
- 遍历输入数组,从索引 1 开始(因为初始值已经处理了第一个元素)
- 对于每一个元素
current,检查其是否与end + 1相等。如果是,说明current是连续的数字,更新end变量 - 如果
current不等于end + 1,则表示当前元素不是连续数字的一部分。在这种情况下,调用addRangeToResult函数将当前范围添加到结果数组中,然后重置start和end为当前元素
- 处理最后一个范围:
- 在循环结束后,函数调用
addRangeToResult函数来处理最后一个范围(因为在遍历结束后,可能还有未处理的范围)
- 在循环结束后,函数调用
- 返回结果:
- 最后,函数返回结果数组
result,其中包含了输入数组中的合并后的连续数字范围
- 最后,函数返回结果数组
答案
1 | function mergeConsecutiveNumbers(input) { |
Q18:非递归遍历二叉树
难度:⭐⭐
答案
在数据结构和算法中,非递归遍历二叉树是指通过迭代的方式来遍历二叉树,而不是使用递归的方法。二叉树的遍历方式主要有三种:前序遍历、中序遍历和后序遍历。接下来,我将分别介绍这些遍历方式的非递归实现。
前序遍历(Pre-order Traversal):
在前序遍历中,遍历顺序是根节点 -> 左子树 -> 右子树。非递归实现通常使用栈来模拟递归过程。
1 | function preOrderTraversal(root) { |
中序遍历(In-order Traversal):
在中序遍历中,遍历顺序是左子树 -> 根节点 -> 右子树。非递归实现通常使用栈来辅助遍历。
1 | function inOrderTraversal(root) { |
后序遍历(Post-order Traversal):
在后序遍历中,遍历顺序是左子树 -> 右子树 -> 根节点。非递归实现有几种方法,通常使用栈进行辅助。
1 | function postOrderTraversal(root) { |
通过以上的非递归遍历实现,你可以在不使用递归的情况下对二叉树进行前序遍历、中序遍历和后序遍历。这些实现都使用了栈来模拟递归过程,以达到非递归遍历的目的
Q19 :写一个返回数据类型的函数,要求自定义的类实例化的对象返回定义的类名
难度:⭐⭐
答案
1 | // 返回数据类型的函数 |
引申
谢谢你提醒我可以详细一些。下面是对比 JavaScript 中几种判断数据类型的方法的表格形式,包括它们的优点和缺点:
| 判断类型方法 | 优点 | 缺点 | 示例代码 |
|---|---|---|---|
typeof | - 简单易用,代码简洁。 - 对于基本数据类型(如字符串、数字、布尔值、函数、未定义)判断准确。 | - 对于对象、数组和 null,返回的结果不准确。- null 的判断结果是 "object",这可能导致混淆。- 无法区分复杂数据类型(如数组和对象)。 | 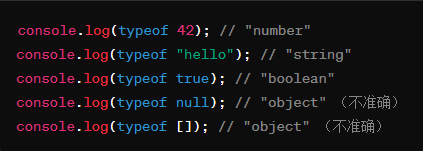 |
instanceof | - 判断对象是否属于某个类(包括内置的类,如 Array、Date)。- 适用于对象的类继承关系判断。 | - 对于原始数据类型(如字符串、数字等)无效。 - 无法区分原始数据类型和其包装对象(例如 String 对象和字符串)。 | 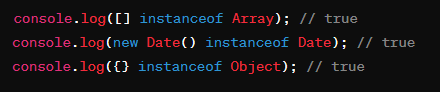 |
Object.prototype.toString.call() | - 对各种类型(包括 null 和 undefined)返回明确的类型信息。- 可以准确判断复杂数据类型(如数组、日期、正则表达式等)。 | - 代码较长,不如 typeof 简洁。 | 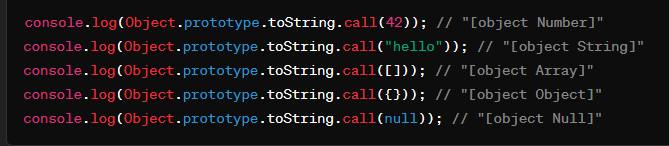 |
Array.isArray() | - 专门用于判断数组,判断准确。 | - 只能判断数组类型,无法判断其他类型。 |  |
Q20:JQuery的链式调用怎么实现的
难度:⭐⭐
解析
1 | // 假设有一个 jQuery 类 |
答案
jQuery 的链式调用是通过在每个 jQuery 方法中返回 jQuery 对象的引用来实现的
当你调用一个 jQuery 方法时,该方法会修改 jQuery 对象的状态,并返回修改后的 jQuery 对象,从而使得可以连续调用其他 jQuery 方法
这种链式调用的实现方式可以使得 jQuery 代码更加清晰和易于编写,同时也能够提高代码的可读性和可维护性
Q21:怎么检测浏览器的版本
难度:⭐⭐
解析
监测浏览器版本是通过获取用户浏览器的 User Agent 字符串,并解析该字符串来获取浏览器的名称和版本信息
通常情况下,User Agent 字符串会包含浏览器的相关信息,包括名称、版本号和操作系统等
以下是一种常见的检测浏览器版本的方法:
- 使用
navigator.userAgent获取用户浏览器的 User Agent 字符串 - 根据 User Agent 字符串中是否包含特定浏览器的标识来确定浏览器的类型。常见的浏览器标识包括
"Chrome"、"Firefox"、"Safari"、"Edge"、"MSIE"等 - 通过正则表达式匹配来提取出浏览器的版本信息。通常情况下,浏览器的版本号会跟在浏览器名称后面,并且以斜杠
/分隔,例如"Chrome/92.0.4515.159" - 根据不同的浏览器类型和版本信息,进行相应的处理或输出
这种方法是一种基于 User Agent 字符串的检测浏览器版本的常用方法。然而,需要注意的是,User Agent 字符串可以被篡改,因此在实际应用中可能会存在一定的不准确性
答案
1 | // 获取浏览器的 user agent 字符串 |
引申
Feature Detection(特性检测)
通过检测浏览器是否支持某些特定的 JavaScript 特性或 API 来判断浏览器版本
不同版本的浏览器可能会实现不同的特性或 API,因此可以根据特性的支持情况来推断浏览器版本
这种方法不依赖于 User Agent 字符串,更加可靠,但需要了解不同浏览器版本对特性的支持情况
嗅探技术(Sniffing)
通过检测浏览器的行为、属性或功能来确定其类型和版本
例如,可以检测浏览器的渲染引擎、JavaScript 引擎、CSS 属性支持情况等
嗅探技术相对复杂,需要针对不同浏览器进行详细的测试和分析,但可以提供更准确的浏览器识别结果
服务端检测
在服务器端进行浏览器检测
当浏览器向服务器发送请求时,服务器可以通过解析请求的 User Agent 字符串来确定浏览器类型和版本,并返回相应的内容或页面
这种方法相对可靠,但需要在服务器端进行处理,可能会增加服务器的负载和复杂度
Q22:什么是单点登录,以及如何进行实现
难度:⭐⭐
解析
答案
一、单点登录是什么
单点登录(Single Sign On),简称为 SSO,是目前比较流行的企业业务整合的解决方案之一
SSO的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统
SSO 一般都需要一个独立的认证中心(passport),子系统的登录均得通过passport,子系统本身将不参与登录操作
当一个系统成功登录以后,passport将会颁发一个令牌给各个子系统,子系统可以拿着令牌会获取各自的受保护资源,为了减少频繁认证,各个子系统在被passport授权以后,会建立一个局部会话,在一定时间内可以无需再次向passport发起认证
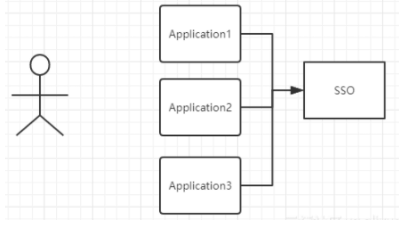
上图有四个系统,分别是Application1、Application2、Application3、和SSO,当Application1、Application2、Application3需要登录时,将跳到SSO系统,SSO系统完成登录,其他的应用系统也就随之登录了
举个例子
淘宝、天猫都属于阿里旗下,当用户登录淘宝后,再打开天猫,系统便自动帮用户登录了天猫,这种现象就属于单点登录
二、如何实现
同域名下的单点登录
cookie的domin属性设置为当前域的父域,并且父域的cookie会被子域所共享。path属性默认为web应用的上下文路径
利用 Cookie 的这个特点,没错,我们只需要将Cookie的domain属性设置为父域的域名(主域名),同时将 Cookie的path属性设置为根路径,将 Session ID(或 Token)保存到父域中。这样所有的子域应用就都可以访问到这个Cookie
不过这要求应用系统的域名需建立在一个共同的主域名之下,如 tieba.baidu.com 和 map.baidu.com,它们都建立在 baidu.com这个主域名之下,那么它们就可以通过这种方式来实现单点登录
不同域名下的单点登录(一)
如果是不同域的情况下,Cookie是不共享的,这里我们可以部署一个认证中心,用于专门处理登录请求的独立的 Web服务
用户统一在认证中心进行登录,登录成功后,认证中心记录用户的登录状态,并将 token 写入 Cookie(注意这个 Cookie是认证中心的,应用系统是访问不到的)
应用系统检查当前请求有没有 Token,如果没有,说明用户在当前系统中尚未登录,那么就将页面跳转至认证中心
由于这个操作会将认证中心的 Cookie 自动带过去,因此,认证中心能够根据 Cookie 知道用户是否已经登录过了
如果认证中心发现用户尚未登录,则返回登录页面,等待用户登录
如果发现用户已经登录过了,就不会让用户再次登录了,而是会跳转回目标 URL,并在跳转前生成一个 Token,拼接在目标URL 的后面,回传给目标应用系统
应用系统拿到 Token之后,还需要向认证中心确认下 Token 的合法性,防止用户伪造。确认无误后,应用系统记录用户的登录状态,并将 Token写入Cookie,然后给本次访问放行。(注意这个 Cookie 是当前应用系统的)当用户再次访问当前应用系统时,就会自动带上这个 Token,应用系统验证 Token 发现用户已登录,于是就不会有认证中心什么事了
此种实现方式相对复杂,支持跨域,扩展性好,是单点登录的标准做法
不同域名下的单点登录(二)
可以选择将 Session ID (或 Token )保存到浏览器的 LocalStorage 中,让前端在每次向后端发送请求时,主动将LocalStorage的数据传递给服务端
这些都是由前端来控制的,后端需要做的仅仅是在用户登录成功后,将 Session ID(或 Token)放在响应体中传递给前端
单点登录完全可以在前端实现。前端拿到 Session ID(或 Token )后,除了将它写入自己的 LocalStorage 中之外,还可以通过特殊手段将它写入多个其他域下的 LocalStorage 中
关键代码如下:
1 | // 获取 token |
前端通过 iframe+postMessage() 方式,将同一份 Token 写入到了多个域下的 LocalStorage 中,前端每次在向后端发送请求之前,都会主动从 LocalStorage 中读取Token并在请求中携带,这样就实现了同一份Token 被多个域所共享
此种实现方式完全由前端控制,几乎不需要后端参与,同样支持跨域
三、流程
单点登录的流程图如下所示:
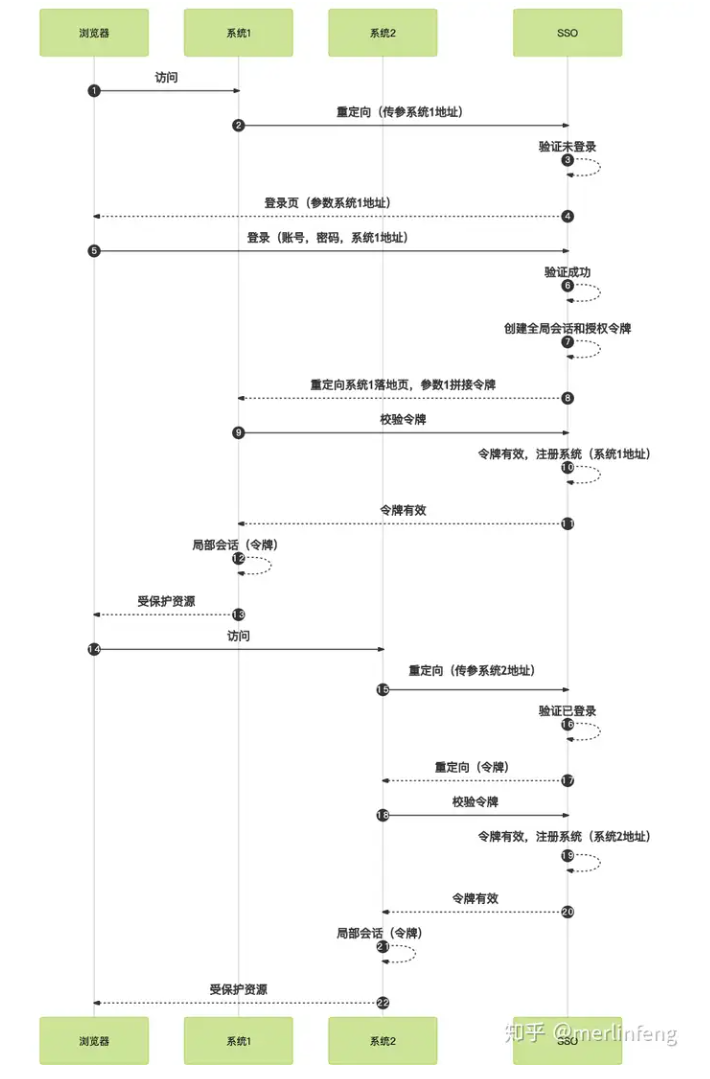
- 用户访问系统1的受保护资源,系统1发现用户未登录,跳转至sso认证中心,并将自己的地址作为参数
- sso认证中心发现用户未登录,将用户引导至登录页面
- 用户输入用户名密码提交登录申请
- sso认证中心校验用户信息,创建用户与sso认证中心之间的会话,称为全局会话,同时创建授权令牌
- sso认证中心带着令牌跳转会最初的请求地址(系统1)
- 系统1拿到令牌,去sso认证中心校验令牌是否有效
- sso认证中心校验令牌,返回有效,注册系统1
- 系统1使用该令牌创建与用户的会话,称为局部会话,返回受保护资源
- 用户访问系统2的受保护资源
- 系统2发现用户未登录,跳转至sso认证中心,并将自己的地址作为参数
- sso认证中心发现用户已登录,跳转回系统2的地址,并附上令牌
- 系统2拿到令牌,去sso认证中心校验令牌是否有效
- sso认证中心校验令牌,返回有效,注册系统2
- 系统2使用该令牌创建与用户的局部会话,返回受保护资源
用户登录成功之后,会与sso认证中心及各个子系统建立会话,用户与sso认证中心建立的会话称为全局会话
用户与各个子系统建立的会话称为局部会话,局部会话建立之后,用户访问子系统受保护资源将不再通过sso认证中心
全局会话与局部会话有如下约束关系:
- 局部会话存在,全局会话一定存在
- 全局会话存在,局部会话不一定存在
- 全局会话销毁,局部会话必须销毁
引申
Q23:如何判断一个元素是否在可视区域中
难度:⭐⭐
答案
element.getBoundingClientRect()使用
element.getBoundingClientRect()方法,它会返回元素的大小及其相对于视口的位置这个方法返回一个DOMRect对象,包含了
top,right,bottom,left,width,height这些值,其中top和left表示元素左上角相对于视口的位置1
2
3
4
5
6
7
8
9function isInViewport(element) {
const rect = element.getBoundingClientRect();
return (
rect.top >= 0 &&
rect.left >= 0 &&
rect.bottom <= (window.innerHeight || document.documentElement.clientHeight) &&
rect.right <= (window.innerWidth || document.documentElement.clientWidth)
);
}这个函数会返回一个布尔值,如果元素完全在视口内部则为
true,否则为falseIntersection ObserverAPIIntersection ObserverAPI提供了一种异步检测目标元素与其祖先元素或顶级文档视窗(viewport)交叉状态变化的方式这种方法非常适合用来实现懒加载、无限滚动等功能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// 通过IntersectionObserver构造函数创建一个观察者对象
let observer = new IntersectionObserver((entries, observer) => {
entries.forEach(entry => {
// 如果entry.isIntersecting为true,表示元素进入可视区
if (entry.isIntersecting) {
console.log('元素已进入可视区域');
// 做一些操作,比如加载图片等
// 完成操作后,可以取消观察
observer.unobserve(entry.target);
}
});
});
// 调用observe方法来观察一个元素
observer.observe(document.querySelector('#yourElementId'));
Q24:什么是防抖和节流,以及如何编码实现
难度:⭐⭐
解析
答案
是什么
本质上是优化高频率执行代码的一种手段
如:浏览器的 resize、scroll、keypress、mousemove 等事件在触发时,会不断地调用绑定在事件上的回调函数,极大地浪费资源,降低前端性能
为了优化体验,需要对这类事件进行调用次数的限制,对此我们就可以采用throttle(节流)和debounce(防抖)的方式来减少调用频率
| 属性/技术 | 防抖 (Debouncing) | 节流 (Throttling) |
|---|---|---|
| 定义 | 在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时。 | 在固定时间间隔内只执行一次事件回调。 |
| 相同点 | 两者都是性能优化的技术,用于减少事件处理器执行的频率。 | 同左。 |
| 不同点 | 防抖关注于延迟执行。一段时间内的多次操作只会执行最后一次。 | 节流关注于定时执行。一段时间内的操作,无论触发多少次,只会定期执行一次。 |
| 应用场景 | - 搜索框搜索输入。(减少请求次数) - 窗口大小调整(resize)。(避免重绘和重流) - 表单验证。(停止输入一段时间后进行验证) | - 滚动加载,滚动事件的无限加载。(比如滚动到页面底部自动加载内容) - 轮播图用户快速多次点击箭头按钮。(限制用户点击频率) - 测量滚动位置。(例如固定时间内只计算一次滚动距离) |

举例:
每天上班大厦底下的电梯。把电梯完成一次运送,类比为一次函数的执行和响应
假设电梯有两种运行策略 debounce 和 throttle,超时设定为15秒,不考虑容量限制
电梯第一个人进来后,15秒后准时运送一次,这是节流
电梯第一个人进来后,等待15秒。如果过程中又有人进来,15秒等待重新计时,直到15秒后开始运送,这是防抖
代码实现
防抖
立即执行
事件触发后立即执行,然后n秒内不再执行
这种实现方式的效果是,事件触发后立即执行,然后在等待的n秒内如果事件又被触发则重新等待n秒
1
2
3
4
5
6
7
8
9
10
11
12
13function debounce(func, wait) {
let timeout;
return function() {
const context = this;
const args = arguments;
if (timeout) clearTimeout(timeout);
let callNow = !timeout;
timeout = setTimeout(() => {
timeout = null;
}, wait);
if (callNow) func.apply(context, args);
}
}非立即执行
事件触发后不立即执行,等待n秒后执行,如果在这n秒内又触发了事件,则重新开始等待
这种实现方式的效果是,当事件在n秒内没有再次被触发,才会执行回调函数。即当你滚动滚动条时,滚动结束后n秒再执行,如果滚动过程中又滚动了,那么重新等待n秒
1
2
3
4
5
6
7
8
9
10
11function debounce(func, wait) {
let timeout;
return function() {
const context = this;
const args = arguments;
if (timeout) clearTimeout(timeout);
timeout = setTimeout(() => {
func.apply(context, args);
}, wait);
}
}
节流
时间戳方式
时间戳方式的节流函数会立即执行第一次触发的事件,然后如果在设定的时间间隔内再次触发事件,这次触发的事件不会被执行
只有当过了设定的时间间隔后,才会再次执行事件处理函数
1
2
3
4
5
6
7
8
9
10
11
12function throttle(func, wait) {
let previous = 0;
return function() {
const now = Date.now();
const context = this;
const args = arguments;
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
}
}定时器方式
定时器方式的节流函数会在第一次触发事件时不立即执行事件处理函数,而是设置一个延时,等待指定的时间间隔后执行。如果在这个延时期间内再次触发了事件,这次触发的事件不会被执行
1
2
3
4
5
6
7
8
9
10
11
12
13function throttle(func, wait) {
let timeout;
return function() {
const context = this;
const args = arguments;
if (!timeout) {
timeout = setTimeout(() => {
timeout = null;
func.apply(context, args);
}, wait);
}
}
}两者结合方式
有时候,为了同时满足立即执行第一次触发的事件和结束触发时还能执行一次事件处理函数的需求,可以将时间戳方式和定时器方式结合起来使用
这种方式结合了两者的优点,第一次触发事件会立即执行,之后如果在设定的时间间隔内再次触发事件,则会延迟执行,确保在结束触发后还能再执行一次
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26function throttle(func, wait) {
let timeout, context, args, previous = 0;
const later = function() {
previous = Date.now();
timeout = null;
func.apply(context, args);
};
return function() {
const now = Date.now();
const remaining = wait - (now - previous);
context = this;
args = arguments;
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
func.apply(context, args);
} else if (!timeout) {
timeout = setTimeout(later, remaining);
}
};
}
Q25:Javascript中如何实现函数缓存?函数缓存有哪些应用场景
难度:⭐⭐
解析
答案
函数缓存,也被称为记忆化(Memoization),是一种优化技术,主要用于存储昂贵函数调用的结果,然后在再次调用同样的输入时直接返回缓存的结果
闭包(Closures)
使用闭包可以缓存函数的计算结果
闭包可以访问函数外部的变量,因此可以将函数结果存储在一个变量中,并在下次执行时首先检查该变量
映射对象(Map Object)
Map对象可以存储键值对,并且能记住原始插入顺序你可以用传递给函数的参数作为键,把函数返回的结果作为值来进行存储
高阶函数(Higher Order Functions)
可以创建一个高阶函数,它接受一个函数并返回一个新的函数
这个新函数会检查是否已经缓存了传递给原函数的特定参数的结果
实现代码
1 | function memoize(fn) { |
使用场景
重复计算
当函数需要多次重复计算相同参数的结果时,函数缓存可以避免重复工作,只需计算一次然后存储结果即可。
昂贵的函数调用
对于计算成本很高的函数,如涉及复杂算法的函数,使用缓存可以减少执行时间。
递归函数
特别是在处理递归函数时,如计算斐波纳契数列等,缓存结果可以大幅度减少计算量。
数据库查询
在需要频繁进行相同查询的数据库操作中,函数缓存可以存储之前的查询结果,减少数据库的压力。
API调用
如果一个API的数据不会频繁更新,通过缓存API调用结果可以节省网络带宽并提高响应速度。
DOM操作的优化
如果有一个函数根据相同参数总是生成相同的DOM结构,可以通过缓存来优化,避免重复的DOM操作。
数据转换
对于数据格式化或转换操作,如日期格式化,如果转换规则复杂且转换对象重复性高,可以用缓存来提高效率。
引申
| 特性 | 闭包 | 高阶函数 | 函数柯里化 |
|---|---|---|---|
| 定义 | 函数嵌套函数,内部函数访问外部变量 | 一个至少满足以下一个条件的函数:接受一个或多个函数作为参数,或者返回一个函数 | 一个将多参数函数转换为一系列使用一个参数的函数的技术 |
| 作用 | 使函数可以访问其定义时的作用域中的变量,即使它在其定义环境外执行 | 抽象或封装行为,可以用函数作为参数或返回新的函数来构建更加模块化的代码 | 分解复杂的函数参数,使得函数变得易于处理,易于复用,并且能够逐步应用函数 |
| 状态保持 | 可以记住和访问创建它的函数的局部变量,参数和其他闭包 | 不一定保持任何状态,可以是无状态的,仅用于抽象计算步骤或创建新的函数 | 不直接关注状态,而是关注参数的重组和分配 |
| 返回值 | 会返回一个函数,这个函数可以访问创建它时的环境 | 可以返回函数,也可以返回其他任何类型的值 | 返回接收下一个参数的新函数,直到所有参数被”消耗” |
| 参数处理 | 参数在闭包创建时确定,并在闭包的上下文中保持不变 | 参数的处理取决于具体的高阶函数实现,并非固定模式 | 每次调用仅接受一个参数,并返回接受下一个参数的新函数 |
| 使用场景 | 用于创建私有变量和方法,保存状态,实现模块化 | 用于函数抽象和复用,函数组合,以及处理不确定数量的参数 | 用于固定某些参数,简化多参数函数的逆复,以及函数的偏应用 |
Q26:如何有顺序的执行10个异步任务
难度:⭐⭐⭐
答案
Async/Await1
2
3
4
5
6
7
8
9
10
11
12
13
14async function asyncTask(i) {
return new Promise((resolve) => setTimeout(() => {
console.log('Task ' + i);
resolve(i);
}, 1000));
}
async function runTasks() {
for (let i = 1; i <= 10; i++) {
await asyncTask(i); // 等待当前任务完成
}
}
runTasks(); // 启动任务在这个例子中,
await关键字使得 JavaScript 引擎等待每个asyncTask完成之后再继续循环Promise 链通过在每个异步操作上调用
.then()方法,可以确保它们按顺序执行1
2
3
4
5
6
7
8
9
10
11
12function asyncTask(i) {
return new Promise((resolve) => setTimeout(() => {
console.log('Task ' + i);
resolve();
}, 1000));
}
let promise = Promise.resolve();
for (let i = 1; i <= 10; i++) {
promise = promise.then(() => asyncTask(i));
}在这个例子中,每个任务都将在前一个任务解决后启动
使用递归
通过递归函数顺序执行异步任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16function asyncTask(i) {
return new Promise((resolve) => setTimeout(() => {
console.log('Task ' + i);
resolve(i);
}, 1000));
}
function runTasks(i) {
if (i > 10) {
return;
}
asyncTask(i).then(() => runTasks(i + 1));
}
runTasks(1);当一个任务完成,它会调用
runTasks来启动下一个任务
Q27:javascript里面怎么取消请求
难度:⭐⭐⭐
答案
取消
XMLHttpRequest请求对于
XMLHttpRequest对象,我们可以使用abort方法来取消请求1
2
3
4
5
6
7
8
9
10
11
12
13
14
15var xhr = new XMLHttpRequest();
xhr.open("GET", "https://www.example.com/api", true);
xhr.onload = function(e) {
// 请求成功的处理
};
xhr.onerror = function(e) {
// 请求失败的处理
};
xhr.send(null);
// 在需要取消请求的时候调用
xhr.abort();在这个例子中,调用
xhr.abort()会立即终止请求,然后触发onabort事件加上对
onerror的监听可以确保所有的异常情况都有对应的处理取消
Fetch请求通过使用
AbortController和它的signal属性,可以取消一个fetch请求1
2
3
4
5
6
7
8
9
10
11
12
13
14
15const controller = new AbortController();
const signal = controller.signal;
fetch('https://www.example.com/api', { signal }).then(response => {
// 请求成功的处理
}).catch((e) => {
if (e.name === 'AbortError') {
console.log('Fetch operation was aborted');
} else {
// 其它错误的处理
}
});
// 在需要取消请求的地方调用
controller.abort();在此示例中,创建了一个
AbortController,并将其signal属性传递给fetch要取消请求,在合适的时机调用
controller.abort()取消
Axios请求1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16const controller = new AbortController();
axios.get('https://www.example.com/api', {
signal: controller.signal
}).then(response => {
// 请求成功的处理
}).catch(error => {
if (axios.isCancel(error)) {
console.log('Request canceled', error.message);
} else {
// 其他错误的处理
}
});
// 当需要取消请求时执行
controller.abort();我们创建了一个
AbortController的实例,并将它的signal属性作为配置选项传递给 Axios 的请求方法当调用
controller.abort()方法时,如果请求仍在进行中,它将被取消,并且catch块将捕获到一个异常,其中axios.isCancel(error)可以检测这个异常是否是因为请求被取消造成的您应该确保使用的 Axios 版本支持
AbortController这个特性自 Axios v0.19.0 起被引入
Q28:如何让 var [a, b]={a: 1,b: 2}解构赋值成功
难度:⭐⭐⭐
解析
答案
在浏览器运行的时候,报错如下:
1 | const obj = { |
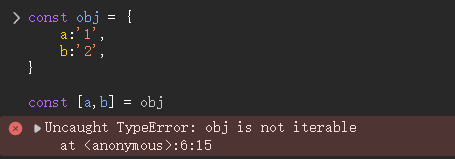
它告诉我们obj这个对象是不可迭代的,只要改成可迭代的,就可以解决这个问题
要想满足迭代协议需要对象身上有一个名为[Symbol.iterator]的方法
再使用for..of或者解构赋值的时候会隐式的调用这个方法,得到一个迭代对象,通过迭代对象的next方法判断当前是否完成迭代和具体迭代的值
也就是说我们要在obj上添加[Symbol.iterator]方法并且完成next方法的逻辑
1 | const obj = { |
引申
可迭代协议的概念( MDN )
可迭代协议是JavaScript中规定的一套标准,它允许对象通过特定的方法定义它们的迭代行为,即规定了对象如何被for...of这样的迭代语句遍历。这个协议主要涉及到两个部分:
迭代器方法 (
@@iterator):对象或其原型链中的某个对象必须有一个名为
Symbol.iterator的属性,该属性是一个无参数函数,它返回一个迭代器对象。当对象需要被迭代时,例如在for...of循环中,这个方法会被调用迭代器对象:
该对象必须遵守迭代器协议,具体来说,需要有一个
next()方法,该方法在每次迭代时被调用。每次调用next()方法时,迭代器对象返回另一个称为迭代结果的对象。迭代结果对象必须具有两个属性:value:迭代的当前值done:布尔值,如果迭代器已经遍历了迭代对象所有值,则为true;如果迭代还未结束,则为false
通过实现这个协议,任何对象都可定制它在迭代时产生值的序列,成为可迭代的
例如,数组和字符串是可迭代的,因为它们的原型链上都有Symbol.iterator属性
1 | let arr = [1, 2, 3]; |
在此示例中,数组arr是内建可迭代对象,它的Symbol.iterator方法返回一个迭代器对象it,我们可以手动调用next()方法来迭代数组
如果需要让一个自定义对象满足可迭代协议,可以定义如下:
1 | const obj = { |
在这个例子中,我们创建了一个普通对象,并给它添加了一个[Symbol.iterator]属性,从而使对象变成可迭代的
通过这种方式,对象就可以用在任何期待可迭代值的JavaScript语言结构中
Q29:前端的页面截图怎么实现
难度:⭐⭐⭐
答案
Canvas
最常见的方式是将需要截图的内容绘制到一个
<canvas>元素上,然后使用canvas.toDataURL()方法获取图像的DataURL,这是一个Base64编码的字符串表示的图片基于此字符串,可以显示图片或者转换成Blob进行下载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24function screenshotDOMElement(element, callback) {
// 将DOM元素渲染到canvas上的函数
html2canvas(element).then(canvas => {
// 转换canvas为DataURL
var dataURL = canvas.toDataURL('image/png');
callback(dataURL);
});
}
// 使用示例
screenshotDOMElement(document.body, function(dataURL){
// 创建一个Image元素
var img = new Image();
img.src = dataURL;
// 将Image元素添加到页面中以显示截图
document.body.appendChild(img);
// 或者创建下载链接以下载截图
var a = document.createElement('a');
a.href = dataURL;
a.download = 'screenshot.png';
a.click();
});需要提醒的是,上面的代码使用了
html2canvas库,它是一个非常流行的库,可以将HTML转换成Canvas图片你需要在你的项目中包含这个库才能使用上述功能
浏览器拓展API
如果你正在开发一个浏览器扩展,你可以利用浏览器提供的API来捕捉当前页面或者页面的部分区域
例如,在Chrome扩展程序中,可以使用
chrome.tabs.captureVisibleTab方法实现截屏这通常用于浏览器插件开发,对于普通的前端网页开发并不适用
1
2
3
4
5
6chrome.tabs.captureVisibleTab(null, {}, function (image) {
// image是一个base64编码的DataURL
var screenshotUrl = image;
// 下面你可以将截图DataURL用于不同的目的,例如显示或下载
});使用这个API,用户的浏览器必须安装相应的扩展,并且在扩展的权限设置中允许这种截图行为
注意
- 如果页面中有跨域内容,使用Canvas进行截图可能会遇到安全限制
- 上述方法仅适合静态内容的截图。如果页面有复杂的动态效果或者视频等流媒体内容,可能无法准确捕获
- 对于特权环境(如浏览器扩展),可能有额外的API用于截图
- 用户隐私应予以考虑,不应在用户不知情或未经允许的情况下进行截图
Q30:怎么实现虚拟列表
难度:⭐⭐⭐
解析
虚拟列表(Virtual List)或虚拟滚动(Virtual Scrolling)是一种极其有效的前端性能优化技术,专门用于优化长列表数据的渲染性能
当面对需要渲染成千上万条数据项的列表时,虚拟列表技术通过只渲染当前视口(viewport)内以及少量缓冲区内的列表项,而不是整个列表的数据项,来显著提高页面的渲染效率及性能
核心概念
渲染优化
虚拟列表通过减少实际渲染的DOM节点数量来降低浏览器的负担,使得即使是数据量极大的列表页也能实现流畅的滚动和交互体验
动态渲染
随着用户滚动,应用程序会根据视口的变化动态地添加或移除列表项,确保在任何时候,DOM中的节点数量保持恒定
优点与缺点
优点
性能提升
显著减少了待渲染的DOM元素数量,提高页面渲染性能
用户体验增强
页面滚动流畅,减少了内存的占用,提高了页面响应速度
缺点
实现复杂度
动态计算可见项、处理滚动事件等,实现相对较为复杂
滚动位置误差
尤其在列表项高度不一致时,可能会导致滚动位置的计算误差
应用场景
电商网站的商品列表
展示成千上万的商品信息
后台系统的数据表格
处理大量的数据展示
社交媒体信息流
如新闻、文章列表或社交动态的无限滚动加载
虽然可以手动实现虚拟列表,但大多数开发者倾向于使用现成的库来简化开发流程,例如react-window和react-virtualized等库,它们提供了开箱即用的虚拟列表实现方案,大大降低了复杂度
答案
实现虚拟列表涉及以下关键步骤与技术:
计算可见区域
根据视口大小和滚动位置来计算当前应该渲染哪些列表项
渲染策略
仅渲染视口内的数据项,对于非可见区域的数据,通过占位符或者估算高度来确保滚动条正常
动态调整
根据滚动位置动态加载新的列表项并回收离开视口的旧数据项
优化技术
虚拟DOM
降低重绘与回流,提升性能
懒加载
延迟渲染非可见区域的数据,减少网络和资源消耗
缓存机制
缓存已渲染的列表项,提高滚动性能
预测加载
根据用户的滚动行为预测接下来的数据需求,提前加载数据
具体实现
Q31:如何判断某个字符串长度(要求支持表情)
难度:⭐⭐⭐
答案
JavaScript 的 length 属性在处理包含四字节 Unicode 字符(例如表情符号)的字符串时可能不会返回预期的结果,原因是 length 属性会将四字节的 Unicode 字符计算为 2 个字符
所以如果需要准确获得包含表情符号的字符串长度,我们要用到“展开”操作符 (...) 和 Array 对象的 length 属性
1 | let str = "Hello, World! 😊"; |
这段代码会将字符串里的每个字符(包括四字节 Unicode 字符)都单独展开成独立的数组元素,然后使用 length 属性统计元素的数量,避免了四字节字符被错误地计为2个字符的问题
Q32:如何判断页面是通过PC端还是移动端访问
难度:⭐⭐⭐
答案
navigator.userAgent1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17function detectDevice() {
let userAgent = navigator.userAgent;
if (userAgent.match(/Android/i)
|| userAgent.match(/webOS/i)
|| userAgent.match(/iPhone/i)
|| userAgent.match(/iPad/i)
|| userAgent.match(/iPod/i)
|| userAgent.match(/BlackBerry/i)
|| userAgent.match(/Windows Phone/i)) {
return 'Mobile Device';
}
else {
return 'Desktop Device';
}
}
console.log(detectDevice());这个
detectDevice()函数在执行时会检查navigator.userAgent是否包含特定的移动设备标识符如果匹配到这些设备标识符中的任何一个,该函数将返回
'Mobile Device'否则,该函数将返回
'Desktop Device'这个方法并不是
100%准确的,因为用户代理字符串可以被浏览器设置项或恶意用户修改然而,这仍然是一个大多数情况下有效的方法,用于判断访问者使用的是桌面还是移动设备
使用CSS媒体查询
通过CSS媒体查询判断窗口的大小,从而对移动设备和桌面设备采取不同的样式
1
2
3@media only screen and (max-width: 768px) {
/* 在这里放置移动端的CSS */
}检查屏幕宽度
移动设备通常支持触摸事件,而桌面则依赖于鼠标事件,所以你可以侦测页面是否可以进行触摸事件来判定
1
2
3
4
5if (window.innerWidth <= 768) {
// 移动端执行的代码
} else {
// 桌面端执行的代码
}触摸事件检测
移动设备通常支持触摸事件,而桌面则依赖于鼠标事件,所以可以侦测页面是否可以进行触摸事件来判定
1
2
3
4
5
6
7function isTouchDevice() {
return (
('ontouchstart' in window)
|| (navigator.MaxTouchPoints > 0)
|| (navigator.msMaxTouchPoints > 0)
)
}使用库或框架
现成的库,如Modernizr、WURFL.js等,可以帮助你检测设备的类型
Q33:实现一个数字转中文的方法
难度:⭐⭐⭐
答案
函数目标与输入检验
这个函数的主要目标是将数字转换为汉字表示的形式
它不仅包括正负整数的转换,也支持处理小数部分以及检查输入数字是否在特定的区间内
最开始的几行代码用于验证输入是否为合法的数字,并确定输入数字是否在函数处理的范围内(本例中为-1亿到1亿)
javascript
1 | if (isNaN(num)) return '输入不是一个有效的数字'; |
负数处理
接下来,函数检查数字是否为负
如果是负数,它会标记一个负数标志为true并将数字转换为正数以便后续处理
1 | let negative = false; |
整数部分转换
函数中的getIntegerChn辅助函数负责将数字的整数部分转换成汉字
这一过程通过递归地处理数字的每四位(即在中文中的“万”与“亿”单位间的分割点)来完成
它首先将数字分解成小于10000的块,并为每个块生成对应的中文表示,然后根据其在原数中的位置添加适当的单位(如“万”、“亿”等)
1 | const getIntegerChn = (intNum) => { ... }; |
小数部分转换
如果数字有小数点,getDecimalChn函数负责将小数点后的每位数字转换为相应的汉字,并在前面加上“点”字以区分整数和小数部分
1 | const getDecimalChn = (str) => { ... }; |
负数的最终表示
在整数和小数部分都转换完成后,如果最初标记的负数标志为true,则在最终的中文字符串前加上“负”字
1 | function convertToChinese(num) { |
Q34:用js实现二叉树的定义和基本操作(待完善)
难度:⭐⭐⭐
解析
答案
引申
二叉树是一种特殊的树形数据结构,其中每个节点最多有两个子节点,通常被称为左子节点和右子节点
按定义,二叉树是空的(即,没有节点)或者由一个根节点和两棵互不相交的、被分别称为左子树和右子树的二叉树组成
详细地说,二叉树的每个节点包含以下部分:
- 数据元素:包含节点值或者其他相关信息的部分
- 左指针:指向左子节点的指针。如果没有左子节点,该指针指向空或者NULL
- 右指针:指向右子节点的指针。如果没有右子节点,该指针指向空或者NULL
二叉树有许多变体,如二叉搜索树、AVL树(自平衡二叉搜索树)、堆(一种特殊的完全二叉树)和红黑树等
其中,二叉搜索树是最常用的一种,它的特点是任意节点的值都大于或等于其左子树中存储的值,并且小于或等于其右子树中存储的值
二叉树的优势在于其查找、插入、删除的平均和最佳时间复杂度可以达到O(log n)(其中n代表树中节点的数量),这归功于二叉树数据结构的特性使查找路径大大缩短
但是,为了保持树的平衡(即保持左右两边节点数量均衡,避免退化为链),可能需要进行一些额外操作
二叉树可被用来实现二叉搜索树、表达式解析树、堆和B+树(一种用于数据库和文件系统的数据结构)等等
Q35:查找岛屿数量
难度:⭐⭐⭐
1 | // 1、给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。 |
解析
在计算二维网格中岛屿的数量问题中,主要有两种搜索方法来遍历岛屿:
深度优先搜索(DFS, Depth-First Search)
深度优先搜索是以垂直的方式进行探索。它从一个节点开始,尽可能深地搜索每一个分支,直到到达底部,然后回溯并探索下一条分支在岛屿数量的问题中,DFS可以从任一未访问过的陆地出发,尽可能探索与之相连的所有陆地,然后将其标记为已访问
DFS通过递归或栈实现
广度优先搜索(BFS, Breadth-First Search)
广度优先搜索是以水平的方式进行探索它从一个节点开始,首先访问所有邻近的节点,即先宽后深地探索每一层
在岛屿数量的问题中,BFS可以从任一未访问过的陆地出发,一层一层地探索所有相邻的陆地,并将其标记为已访问
BFS通常用队列来实现
答案
使用递归的方式进行深度优先搜索
每当我们遇到”1”(即陆地)时,我们将尝试访问它的所有相邻的”1”(即未访问过的陆地),并将它们标记为已访问,以此来识别一个完整的岛屿
完成对一个岛屿的探索后,我们继续搜索下一个未被访问的”1”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47function numIslands(grid) {
// 辅助函数用于执行深度优先搜索
function dfs(i, j) {
// 检查越界情况以及是否是水域或已访问过的陆地
if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] === '0') {
return;
}
// 将当前位置标记为已访问
grid[i][j] = '0'; // 通过将1修改为0来标记已访问
// 访问四个方向的相邻陆地
dfs(i+1, j); // 下
dfs(i-1, j); // 上
dfs(i, j+1); // 右
dfs(i, j-1); // 左
}
if (!grid || !grid.length) return 0;
let count = 0; // 计数器,用于统计岛屿数量
for (let i = 0; i < grid.length; i++) {
for (let j = 0; j < grid[i].length; j++) {
if (grid[i][j] === '1') { // 发现未访问的陆地,启动深度优先搜索
dfs(i, j);
count++; // 完成一个岛屿的搜索,岛屿数量加1
}
}
}
return count;
}
// 示例1
const grid1 = [
["1", "1", "1", "1", "0"],
["1", "1", "0", "1", "0"],
["1", "1", "0", "0", "0"],
["0", "0", "0", "0", "0"]
];
console.log(numIslands(grid1)); // 返回结果 1
// 示例2
const grid2 = [
["1", "1", "0", "0", "0"],
["1", "1", "0", "0", "0"],
["0", "0", "1", "0", "0"],
["0", "0", "0", "1", "1"]
];
console.log(numIslands(grid2)); // 返回结果 3这段代码首先定义了一个
dfs函数,用于实现深度优先搜索并标记已访问的陆地然后,我们遍历整个网格,每次遇到”1”(未访问过的陆地)时,使用
dfs函数搜索整个岛屿,并通过将”1”标记为”0”来标记已访问的陆地遍历过程中每完成对一个岛屿的探索,就将岛屿数量加一
使用广度优先搜索(BFS)
我们通常会用队列来追踪需要探索的陆地
从遇到初始的一个“1”开始,我们将其添加到队列中,然后按层序遍历相邻的格子,将遇到的所有“1”都置为“0”以防重复计数,直到队列为空
这样,每完成一轮循环,就能识别并计数一个岛屿
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51function numIslands(grid) {
if (!grid || !grid.length) return 0;
const rows = grid.length;
const cols = grid[0].length;
const dirs = [[-1, 0], [1, 0], [0, -1], [0, 1]]; // 上下左右移动的方向
let count = 0;
for (let i = 0; i < rows; i++) {
for (let j = 0; j < cols; j++) {
if (grid[i][j] === '1') {
count++; // 找到一个岛屿,岛屿数量加1
grid[i][j] = '0'; // 标记为已访问
const queue = [[i, j]]; // 使用数组模拟队列,存储岛屿中的陆地坐标
while (queue.length > 0) {
const [x, y] = queue.shift(); // 从队列中取出一个陆地坐标
// 检查此陆地的所有相邻陆地
for (let [dx, dy] of dirs) {
const nx = x + dx, ny = y + dy;
if (nx >= 0 && nx < rows && ny >= 0 && ny < cols && grid[nx][ny] === '1') {
grid[nx][ny] = '0'; // 标记为已访问
queue.push([nx, ny]); // 相邻的陆地入队
}
}
}
}
}
}
return count;
}
// 示例1
const grid1 = [
["1", "1", "1", "1", "0"],
["1", "1", "0", "1", "0"],
["1", "1", "0", "0", "0"],
["0", "0", "0", "0", "0"]
];
console.log(numIslands(grid1)); // 返回结果 1
// 示例2
const grid2 = [
["1", "1", "0", "0", "0"],
["1", "1", "0", "0", "0"],
["0", "0", "1", "0", "0"],
["0", "0", "0", "1", "1"]
];
console.log(numIslands(grid2)); // 返回结果 3在这段代码中,
dirs数组定义了可以移动的方向,即上下左右每次发现一个“1”后,都开始一个新的BFS过程:首先将其标记为“0”,然后将它的坐标加入队列中
在队列不为空的情况下循环,每次从队列中取出一个坐标,再将其相邻的未标记的陆地坐标入队,同时将这些陆地标记为“0”以表示已访问
引申
时间复杂度和空间复杂度是用来评估算法效率的两个标准。想象一下,你在厨房做饭:
时间复杂度
就像是完成菜肴所需要的总时间
简单的菜,比如煮鸡蛋,可能只需要几分钟
但如果是做一个复杂的烤鸡大餐,可能需要几个小时
在计算机的世界里,时间复杂度帮助我们了解一个程序运行完成需要多长时间
评估标准
确定算法的基本操作
识别算法中执行最频繁的操作
比如在排序算法中,基本操作可能是比较或交换元素
分析操作的数量
计算输入数据大小为n时,基本操作执行了多少次
假设操作数量为
f(n)考虑最坏情况
通常我们评估算法的时间复杂度时,考虑的是最坏的情况
即对于给定大小的输入,算法所需时间的最大值
简化表达式
在
f(n)中去掉常数项和低阶项,保留最高阶项,并注意它前面的系数也不重要因为时间复杂度关注的是随着输入规模n的增长,算法所需时间的变化趋势
使用大O符号
得到简化后的表达式并采用大O符号来描述算法的时间复杂度
例如,如果操作数量
f(n)可被简化为2n^2 + 3n + 5,则算法的时间复杂度是O(n^2)
空间复杂度
则像是你在做饭时占用的厨房空间大小
如果你只是煮个鸡蛋,可能只需要一个小锅
但如果是准备一个大餐,你可能需要整个厨房的空间
在计算机中,空间复杂度告诉我们运行一个程序需要多少内存空间
评估标准
考虑所有内存使用
算法可能使用内存来存储各种变量、数组、来自外部输入的数据和递归栈
区分临时和持久空间使用
有些内存使用在算法执行完后就不再需要了,这是临时内存使用
有些可能是算法的输出,或者是算法运行过程中必须长期保留的,这是持久内存使用
计算所有部件的总空间
评估由输入大小n导致的总内存使用情况
这通常包括输入数据结构的大小,加上算法内部额外创建的数据结构大小
简化表达式
和时间复杂度一样,去掉表达式中的常量项和低阶项,只保留最高阶项
使用大O符号
最后,使用大O符号来描述空间复杂度
例如,如果一个算法只需要一个大小与输入大小n成比例的数组,那么空间复杂度就是
O(n)
Q36:计算背包
难度:⭐⭐⭐
1 | // 有 N 件物品和一个容量是 V 的背包。每件物品有且只有一件。 |
解析
解决这类背包问题,有几种不同的方法,通常包括动态规划、回溯、贪心算法等。下面我将概述几种常用的解决方法:
动态规划(DP)
动态规划是解决背包问题最经典也是最有效的方法之一
它主要有两种方式:0-1背包和完全背包
对于你的问题,我们使用0-1背包的思路,因为每件物品只能选择一次
0-1背包问题
可以用二维数组
dp表示,其中dp[i][j]表示从前i个物品中挑选,总体积不超过j的条件下的最大价值状态转移方程为:
dp[i][j] = max(dp[i-1][j], dp[i-1][j-v[i]] + w[i])
这种方法的时间复杂度和空间复杂度均为O(NV),N是物品数量,V是背包容量
动态规划(空间优化)
基于上面的动态规划方法,可以对其进行空间优化,将二维数组压缩为一维数组。优化后,使用单个数组
dp[j]表示总体积不超过j的条件下的最大价值,状态转移方程变为:dp[j] = max(dp[j], dp[j-v[i]] + w[i])。空间复杂度降低为O(V)。
贪心算法
贪心算法是另一种思路,它不总能得到最优解,但在某些情况下计算效率较高
对于物品选择问题,一个简单的贪心策略可能是按价值密度(价值除以体积)降序排列物品,然后尽量选择价值密度高的物品装入背包,直到装不下为止
分支限界法
分支限界法是基于队列的宽度优先搜索,它使用“分支”来探索可行的解空间,并使用“限界”来剪枝,不继续探索那些无法得到最优解的分支
这种方法适用于更复杂的背包问题或需要精确解的场景
答案
0-1背包写法
实现0-1背包问题的动态规划算法,你需要构建一个二维数组用来保存每个状态下的最大价值
在实现过程中,我们创建了一个二维数组
dp,其中dp[i][j]代表考虑前i个物品,当背包容量限制为j时我们能够装进背包的最大价值通过填充这个二维数组,我们可以找到最后的解
在结束时,
dp[N][V]就代表了所有物品在不超过背包容量V的条件下能达到的最大总价值注意在真实应用中,为了节省空间,你也可以将这个二维数组压缩到一维数组
这样的优化需要你在更新
dp[j]的时候从后往前更新,这样可以保证状态转移使用的是上个物品的数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29function knapsack(N, V, v, w) {
// dp是一个二维数组,dp[i][j]表示前i个物品,在不超过j的体积下的最大价值
let dp = Array.from({ length: N + 1 }, () => Array(V + 1).fill(0));
// 遍历所有物品
for (let i = 1; i <= N; i++) {
// 遍历所有容量
for (let j = 1; j <= V; j++) {
// 如果当前物品体积大于当前背包容量,不能加入当前物品
if (v[i - 1] > j) {
dp[i][j] = dp[i - 1][j];
} else {
// 状态转移方程
dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - v[i - 1]] + w[i - 1]);
}
}
}
// 最大价值在dp[N][V]中
return dp[N][V];
}
// 示例 1:
let N = 3, V = 4, v = [4, 2, 3], w = [4, 2, 3];
console.log(knapsack(N, V, v, w)); // 输出: 4
// 示例 2:
N = 3, V = 5, v = [4, 2, 3], w = [4, 2, 3];
console.log(knapsack(N, V, v, w)); // 输出: 5完全背包
完全背包问题的关键区别在于每种物品可以选取无限次
在JavaScript中,这种问题的动态规划解法与0-1背包问题类似,但是在更新
dp数组的时候,内部循环会有所不同,因为你需要考虑重复选择某一物品的情况这段代码的处理方式与0-1背包问题的主要差异在于内层循环
j的方向在完全背包问题中,当你在计算
dp[j]时,因为每种类型的物品可以使用多次,所以可以从左到右遍历,并且用自身的先前计算的值来更新后面的值这种处理方式意味着在计算
dp[j]时,可以重复考虑物品i,而这在0-1背包问题中不被允许注意,这里的代码为了简洁明了,省略了物品数量的限制,也就是说,默认情况下每种物品可以无限使用。如果物品有数量限制,解法将不同
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26function completeKnapsack(N, V, v, w) {
// 初始化dp数组,dp[j]代表容量为j的背包能达到的最大值
let dp = new Array(V + 1).fill(0);
// 遍历物品
for (let i = 0; i < N; i++) {
// 遍历背包容量
// 注意:此循环与0-1背包问题相反,我们从小到大遍历
for (let j = v[i]; j <= V; j++) {
// 更新dp[j],选择当前物品i或者不选择,取二者的最大值
dp[j] = Math.max(dp[j], dp[j - v[i]] + w[i]);
}
}
// 返回容量为V的背包的最大价值
return dp[V];
}
// 示例 1:
let N = 3, V = 4, v = [4, 2, 3], w = [4, 2, 3];
console.log(completeKnapsack(N, V, v, w)); // 输出: 4
// 示例 2:
N = 3, V = 5, v = [4, 2, 3], w = [4, 2, 3];
console.log(completeKnapsack(N, V, v, w)); // 输出: 5
// 解释: 选择第二件物品两次空间优化写法
空间优化版本的完全背包问题可以将二维的dp数组压缩为一维数组
空间复杂度从O(NV)降为O(V)
空间优化的关键在于对dp数组定义的更改
在原始方法中,dp是一个二维数组,表示考虑前i个物品在不超过j的体积上的最大价值
优化后,我们在更新dp[j]时,不再需要考虑“前i个物品”这个维度,只需要考虑“不超过j的体积上的最大价值”,因为我们已经在内层循环中涵盖了所有的物品
这种优化极大地节省了空间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24function completeKnapsack(N, V, v, w) {
// 初始化状态数组,dp[v]代表容量为v的背包能装载物品的最大总价值
let dp = new Array(V + 1).fill(0);
// 遍历物品
for (let i = 0; i < N; i++) {
// 从小到大遍历背包容量
for (let j = v[i]; j <= V; j++) {
// 状态转移方程,取最大值
dp[j] = Math.max(dp[j], dp[j - v[i]] + w[i]);
}
}
// 最大背包价值存储在dp[V]
return dp[V];
}
// 示例 1:
let N = 3, V = 4, v = [4, 2, 3], w = [4, 2, 3];
console.log(completeKnapsack(N, V, v, w)); // 输出: 4
// 示例 2:
N = 3, V = 5, v = [4, 2, 3], w = [4, 2, 3];
console.log(completeKnapsack(N, V, v, w)); // 输出: 6,解释:选择第二件物品两次
Q37:全排列
难度:⭐⭐⭐
1 | // 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 |
解析
解决这个问题的关键是采用回溯法
回溯法是一个通过探索所有可能的候选解来找出所有解的策略
如果候选解被确认不是一个解(或者至少不是最后一个解),回溯算法会丢弃它,并且递归地尝试另一个候选解
对于全排列问题,我们可以将问题视为一个树形结构,每一层选择一个不在当前排列中的数字
当我们达到树的底部时,就找到了一个排列,并且回退到上一步,尝试下一个数字
答案
这段代码通过递归函数backtrack遍历所有可能的排列情况
对于每个位置,它都会尝试数组nums中的每一个数字,如果这个数字还没有被使用过(也就是说,它还没有在path中),就将它添加到当前排列(path)中,并继续递归处理下一个位置
当达到一个完整排列时(也就是path的长度与nums的长度相等),就将其加入到结果result中
在处理完一个位置所有可能的数字之后,需要进行回溯(通过path.pop()),也就是撤销上一步的选择,尝试其他选择
1 | function permute(nums) { |
Q38:写一个LRU缓存函数
难度:⭐⭐⭐
解析
LRU缓存,即最近最少使用(Least Recently Used)缓存算法,是一种常用的页面置换算法,选择最近最久未使用的数据进行淘汰
这个算法的主要目的是为了保持最常用的数据在缓存中,而不经常使用的数据会被移出缓存
实现LRU缓存机制的分析过程通常包括以下步骤:
确定数据结构
一个高效的LRU缓存通常需要使用两种数据结构,一种是用于保持插入顺序的链表(比如双向链表),另一种是用于O(1)时间复杂度查找的哈希表
实现插入操作
插入新元素时,我们需要将元素插入到链表的头部
如果缓存已经达到最大容量,我们则移除链表尾部的元素,因为尾部元素是最近最少使用的
同时,需要在哈希表中添加该元素的键和指向链表中元素的指针
实现访问操作
访问元素时,如果元素在缓存中,则需要将其移动到链表的头部,表示它最近被使用过
这也意味着链表的尾部始终表示最久未使用的元素
同步操作
插入和访问操作都需要及时在哈希表和链表之间进行同步,确保两者的数据是一致的
答案
1 | class LRUCache { |
Q39:大文件怎么实现断点续传
难度:⭐⭐⭐
答案
Step 1: 切割文件
利用JavaScript中的
Blob对象的slice方法来切割大文件成为多个小块(即文件片段或file chunks)1
2
3
4
5
6
7
8
9function sliceFile(file, chunkSize) {
let chunks = [];
const size = file.size;
for (let start = 0; start < size; start += chunkSize) {
const chunk = file.slice(start, Math.min(start + chunkSize, size));
chunks.push(chunk);
}
return chunks;
}Step 2: 上传文件切片
上传每个文件切片之前,需要检查服务器上已经上传了哪些切片
通过
fetch或axios等HTTP客户端进行异步上传,并在请求中发送额外信息,如切片序号、文件唯一标识符等1
2
3
4
5
6
7
8
9
10
11
12async function uploadChunks(chunks, fileId) {
for (let i = 0; i < chunks.length; i++) {
const formData = new FormData();
formData.append('chunk', chunks[i]);
formData.append('fileId', fileId);
formData.append('index', i);
// 发送请求到后端
await fetch('/upload', { method: 'POST', body: formData });
// 保存上传进度,用于续传
saveProgress(fileId, i + 1);
}
}Step 3: 保存上传进度
利用
localStorage或其他持久化方法来记录上传的进度,这样在网络断开后可以从中断点继续上传1
2
3function saveProgress(fileId, chunkIndex) {
localStorage.setItem(fileId, chunkIndex);
}Step 4: 断点续传
在上传之前,先向服务器查询文件上传的进度或已上传的切片,从而决定从哪个切片开始上传
1
2
3
4
5
6
7
8async function continueUploading(file, fileId) {
const chunkSize = /* 您设置的切片大小 */;
const chunks = sliceFile(file, chunkSize);
const uploadedChunks = await fetchUploadedChunks(fileId);
const remainingChunks = chunks.slice(uploadedChunks);
await uploadChunks(remainingChunks, fileId);
}Step 5: 后端合并切片
在服务器端,当所有切片上传完成后,需要将这些切片合并成原始的文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15// Node.js 示例
const fs = require('fs');
const path = require('path');
function mergeChunks(chunks, dest) {
const wStream = fs.createWriteStream(dest);
chunks.forEach(chunkPath => {
const data = fs.readFileSync(chunkPath);
wStream.write(data);
fs.unlinkSync(chunkPath); // 删除已合并的切片
});
wStream.end();
}
这些是客户端实现大文件断点续传的基本步骤
实际实现时,你还需要处理异常情况,比如网络错误重试、权限校验、加密等安全措施、以及后端接收切片的API设计等
引申
大文件断点续传是网络传输中的一个术语,指的是在上传或下载大文件时,如果传输中断,则下次可以从中断的地方继续传输,而不是重新开始
底层实现通常依靠的是HTTP协议的范围请求(Range Requests)
工作原理简述:
切片
将整个文件切分成多个小块,每一小块可以单独传输
传输记录
记录每个小块的传输进度,成功或失败
中断和恢复
如果传输中断(比如网络问题、程序关闭等),下次传输可以根据已有的记录,直接从上次中断的小块开始传输
文件重组
当所有的小块都传输完成后,将这些小块重组成原始的大文件
为什么需要断点续传?
节省带宽
如果网络连接不稳定,避免多次上传下载同一个文件的相同部分
提高效率
对于特别大的文件,重新传输全部内容代价很高
用户体验
提供更为流畅和友好的用户体验,特别是移动设备用户在不稳定网络下
断点续传对于提高大文件传输的可靠性和效率至关重要,特别是在容错、网络条件差、数据传输成本高的情况下
Q40:版本号排序
难度:⭐⭐⭐
1 | // 有一组版本号如下 |
答案
这是一个关于版本号排序问题的javascript解决办法
把每一个版本号分解,并使用’.’做成一个数组,这样你具有一个一维数组,其中每个元素是一个数组
然后根据这个数组,你可以使用数组的sort()方法进行排序
在排序函数中,你需要进行一些定制,以确保排序行为符合你的期望
1 | function versionSort(arr) { |
在上述代码中,我们首先定义了一个函数versionSort(),它接收一个版本号数组
在这个函数中我们使用了数组的sort()方法,定制排序函数来对数组排序
在排序函数中,我们首先把版本号分解成多个部分,然后我们对版本号的每一部分进行比较,如果发现某一部分的版本号更大,我们就认定此版本号整体更大,并结束循环和比较
如果所有部分的版本号都相等,我们认定此版本号等于比较的版本号
排序算法拓展Q41-Q42
引申
冒泡排序(Bubble Sort)
通过重复遍历要排序的数列,比较每对相邻元素,如果他们的顺序错误就把他们交换过来
过程类似在水中的气泡逐渐上升
选择排序(Selection Sort)
首先在未排序的数列中找到最小(或最大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾
希尔排序(Shell Sort)
是插入排序的一种更高效的改进版本
希尔排序会先将数列进行分组,然后对每组数据进行插入排序,逐渐缩小分组的间隔进行排序,最终当整个数列基本有序时,再对全体元素进行一次直接插入排序
插入排序(Insertion Sort)
通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入
归并排序(Merge Sort)
归并排序是建立在归并操作上的一种有效的排序算法
该算法是采用分治法(Divide and Conquer)的一个非常典型的应用
快速排序(Quick Sort)
通过选取一个元素作为基准,重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面,此时基准元素在其排好序后的正确位置
堆排序(Heap Sort)
利用堆这种数据结构所设计的,视为一种树形选择排序
计数排序(Counting Sort)
是一个非比较排序,利用数组下标来确定元素的正确位置
桶排序(Bucket Sort)
数组分到有限数量的桶里,每个桶再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)
基数排序(Radix Sort)
按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位
有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序
Q41:实现冒泡排序
难度:⭐⭐⭐⭐⭐
解析
冒泡排序(Bubble Sort)是一种简单的排序算法,它重复地遍历待排序的数组,比较两个相邻的项目,并且在必要时交换它们
每遍历一次都会确保至少有一个元素被移动到其最终位置
实现冒泡排序的步骤解析:
检查输入是否为数组 (
Array.isArray(arr))这个条件判定确保了输入的数据类型是数组
冒泡排序是针对数组设计的,所以这个检查是必要的
空数组或单个元素数组的检查 (
arr.length <= 1)如果数组为空或者仅包含一个元素,则不需要排序,因为它已经是有序的
直接返回原数组
设置
n为数组的长度 (n = arr.length)这个变量后面会被用来确定当前未排序部分的范围
定义
newN变量这个变量用来记录在某一趟遍历中最后一次发生元素交换的位置,表示数组从
newN之后的位置已经是排序好的,下一轮排序时不需要再考虑执行排序的外部循环 (
do...while)外部循环确保排序会持续进行直到没有再需要交换的项,这表示数组已经完全排序
内部循环 (
for循环)在数组的未排序部分进行遍历
类型检查 (
typeof arr[i - 1] !== typeof arr[i])在比较之前确认元素类型相同,以确保排序的有效性和防止JavaScript的强制类型转换可能导致的问题
相邻元素比较 (
arr[i - 1] > arr[i])对当前元素和它之前的元素进行比较。如果前面的元素比当前元素大,它们的位置需要交换
交换元素
使用临时变量
temp来交换两个元素的位置更新
newN设置
newN为这次内部循环中最后一次发生交换的索引
更新
n将
n设置为最后一次发生交换的位置newN,这样下一次外部循环时,只需要检查到newN为止,因为后面的部分已经排序好了循环结束条件 (
newN != 0)如果在一轮完整的遍历中没有发生任何交换,
newN会保持为0,这表明数组已经完全排序,循环可以结束
通过以上步骤,冒泡排序利用交换元素的方式实现了数组的排序
冒泡的“名字”来源于较大元素的“冒泡”效应,因为在每轮遍历中,它们会如气泡一般逐渐“浮”到数组的一端
答案
1 | function bubbleSort(arr) { |
Q42:实现选择排序
难度:⭐⭐⭐⭐⭐
解析
这段代码是选择排序算法的一个 JavaScript 实现
以下是每个主要部分的详细解析:
if (!Array.isArray(arr))这个部分检查输入的参数是否为数组如果不是,就抛出一个
TypeErrorif(arr.length <= 1) return arr;对于空数组或只有一个元素的数组,它们已经被认为是排序过的,所以直接返回就可以了arr.forEach((ele, index) => {...}这个循环检查数组的每个元素是否为数字,并且不是NaN如果元素不是数字或者是
NaN,那么会抛出一个TypeErrorfor (let i = 0; i < n - 1; i++) {...}这个外层循环遍历数组的每个元素,将当前元素设为最小元素for (let j = i + 1; j < n; j++) {...}内层循环遍历当前元素之后的所有元素,如果找到比当前最小元素还小的元素,就更新最小元素的索引if (i !== minIndex) {...}当一次内层循环结束后,如果最小元素不是当前元素(that is, 索引i和minIndex不等),就交换这两个元素的位置这样,第
i个位置上的元素就会是前i+1个元素中的最小元素最后,返回排序后的数组
这个算法的时间复杂度是 O(n^2),其中 n 是数组的长度
尽管选择排序在大多数情况下没有快速排序或归并排序高效,但是它的代码简洁,而且不需要使用额外的内存空间,这使得它在某些情况下仍然是一个很好的选择
答案
1 | function selectionSort(arr) { |
Q43:实现希尔排序
难度:⭐⭐⭐⭐⭐
解析
这段代码是希尔排序算法的实现,我会详细地逐步解析这个过程。
输入验证
首先, 它验证传入的参数是不是一个数组,如果不是数组则抛出错误“
Input must be an array”然后, 它通过一个for循环遍历数组中的每一个元素来验证每个元素是否为数字或字符串
如果数组中存在既不是数字也不是字符串的元素,则抛出错误“
Array elements must be numbers or strings初始化变量
接下来, 定义了数组的长度
len和初始间隔gap间隔的初始值设为1,这个值将用于确定排序时比较元素之间的间隔
动态定义间隔序列
使用一个while循环计算初始的
gap值这个循环基于希尔排序的增量序列计算方法(
gap = gap * 3 + 1),直到gap值不小于数组长度的三分之一这样做是为了从较宽的间隔开始排序,并逐步缩短间隔,最终达到1
进行希尔排序
在外层for循环中,
gap值从初始值开始不断地通过Math.floor(gap / 3)缩小,直到gap值为1这是希尔排序中减小间隔的过程
内层for循环从
i = gap开始迭代数组,这确保了每次比较都是在间隔gap之间进行的最内层for循环将当前元素
arr[j]与距离gap位置之前的对应元素arr[j - gap]进行比较如果
arr[j] < arr[j - gap],则将它们位置互换这个比较和交换过程一直进行,直到当前元素正确地“插入”(实际上是交换到正确位置)或是已经比较到数组的开始位置
结束和返回
当所有的间隔遍历完成,数组将完成排序,并通过
return arr;返回排序后的数组
这就是希尔排序的整个过程,从较大的间隔开始,逐渐缩小间隔进行比较和交换,直至间隔为1,相当于进行了一次插入排序,这时数组已经是排序好的了
这种方法相比于直接插入排序,在同样是基于插入的排序算法中,大大提升了效率
答案
1 | function shellSort(arr) { |
Q44:实现插入排序
难度:⭐⭐⭐⭐⭐
解析
这段代码是插入排序算法的一个实现,适用于JavaScript数组
下面我会逐步解析代码的各个部分:
数组输入验证
- 函数首先检查传入的参数
arr是否为数组类型。如果不是,抛出一个错误
- 函数首先检查传入的参数
元素类型验证与NaN排除
检查数组中的每个元素是否都是数字类型,并且不是
NaN(Not a Number)如果某个元素不是数字或者是
NaN,抛出一个错误
排序逻辑
函数通过两层循环来实现插入排序
外层循环从
arr的第二个元素开始,即索引1,遍历到数组的末尾这个外层循环表示我们从未排序部分取出的待插入元素
内层循环用于找到这个待插入元素在已排序部分的正确位置,并将其插入
在这个过程中,我们把当前元素
current保存在一个变量中,并逐一将已排序的元素向后移动,直到找到一个比current小的元素
一旦找到合适的位置,我们退出内层循环,并将
current放到正确的位置上
插入动作
- 当内层循环完成后,已找到
current元素的插入位置,此时j变量代表current元素应该插入的位置索引 - 最后一步是将
current变量赋值给arr[j+1],这样我们就将元素插入到了数组的正确位置
- 当内层循环完成后,已找到
代码执行后会返回已经排序的数组
插入排序算法利用了事实,即数组的一个子序列(在当前索引之前的元素)已经是排序过的
它在每次迭代中都会将一个新元素插入到已排序的子序列中,直到整个数组排序完成
插入排序的时间复杂度通常是O(n^2),对于较小的或部分排序的数组来说效率是可接受的
对于较大的数组,可能会需要更高效的算法,如快速排序、堆排序或归并排序
答案
1 | function insertionSort(arr) { |
Q45:实现归并排序
难度:⭐⭐⭐⭐⭐
解析
这段代码是一个实现归并排序的JavaScript函数,它包括两个部分:mergeSort主函数和merge辅助函数
让我们逐步来解析一下这段代码
mergeSort函数
这是一个调用归并排序算法的函数,输入参数为一个待排序的数组
arr- 首先,函数通过
Array.isArray(arr)来检查输入是否为数组,然后使用every方法检查数组内的每个元素是否都是有限的数字,对于非数组或者数组中含有无效数字的情况,会抛出一个错误信息 - 如果数组长度小于等于1(表示数组为空或只有一个元素),那就没有必要排序,直接返回原数组
- 然后,函数将待排序的数组从中间拆分为两个子数组,一个包含前半部分的元素,另一个包含后半部分的元素
- 最后,函数递归地对这两个子数组进行排序,然后通过
merge函数将排序后的结果合并在一起
- 首先,函数通过
merge函数
这是一个辅助函数,使用两个已经排序的数组作为输入参数,在这个例子中就是
left和right- 函数首先初始化一个空的结果数组
resultArray和两个从0开始的索引leftIndex和rightIndex - 在接下来的循环中,函数将
left数组中索引为leftIndex的元素和right数组中索引为rightIndex的元素进行比较,较小的那一个将被推入resultArray,并将相应的索引加1,用于追踪两个数组中的比较进度 - 最后,当
left数组和right数组中的元素都被比较过后,剩下的未被比较的元素(其一定会全部在其中一个数组的末尾并且比已经比较过的元素要大)会被加入到结果数组的尾部
- 函数首先初始化一个空的结果数组
答案
1 | function mergeSort(arr) { |
Q46:实现快速排序
难度:⭐⭐⭐⭐⭐
解析
isNumeric(value)这是一个辅助函数,接收一个参数并返回一个布尔值表示该参数是否是finite number(即不是NaN, Infinity或-Infinity)
swap(array, i, j)它是用于交换数组两个索引下的元素的位置
这个函数在排序算法中非常关键
partition(array, left, right)在快速排序中也是一个核心的函数所谓”partition operation”,就是将数组分成两半,使得左边子数组的所有元素都小于右边子数组的所有元素
同时,该函数还会返回一个“pivot index”
这个索引是计算后得到,使得所有比它小的元素都在它的左边,所有比它大的元素都在它的右边
这个pivot就是我们之后进行递归操作的基础
quickSort(array, left, right)是主要的排序函数它首先检查传入的参数是否满足所需的要求,例如数组中的元素是否全为数字等
然后,它使用了划分(partition)操作并得到了一个“pivot index”
在得到这个pivot index后,quickSort函数进行自我调用,对pivot index的左边和右边的子数组分别进行排序
这个过程中的自我调用,就是quickSort中的“递归”部分
快速排序算法是一种非常高效的排序算法
它的基本思想是:通过一次排序将待排序数据分割成独立的两部分,其中一部分数据都比另外一部分的数据小,然后再按此方法对这两部分数据分别进行快速排序,整个过程可以递归进行,以此达到整个数据变成有序序列
答案
1 | function isNumeric(value) { |
Q47:实现堆排序
难度:⭐⭐⭐⭐⭐
解析
heapSort函数这是排序的主函数,接收一个数组
arr作为参数- 输入验证: 首先,进行检查以确保
arr参数是一个数组 - 长度验证: 如果数组长度
<= 1,那就不需要排序,直接返回原数组 - 类型验证: 接下来检查数组中的每个元素都是有限数值
- 构建最大堆: 使用
buildMaxHeap函数把输入数组arr转换为最大堆 - 排序逻辑
- 循环从数组的末尾开始到索引1处结束
- 使用
swap函数将堆顶的最大元素与当前考察位置的元素交换 - 调用
maxHeapify函数将堆顶至考察位置上的部分调整为最大堆
这个函数将按升序排列数组
arr- 输入验证: 首先,进行检查以确保
buildMaxHeap函数这个辅助函数将数组转换成一个最大堆结构
- 从最后一个非叶子节点开始向前(这是由
start = Math.floor(length / 2) - 1决定的),每个节点都进行下沉操作,以保证子节点的值小于这个节点的值
- 从最后一个非叶子节点开始向前(这是由
maxHeapify函数maxHeapify是堆排序核心步骤,它确保堆的属性被维护- 该函数接收一个索引
index和堆的大小heapSize,使用左儿子和右儿子的索引与当前节点的值进行比较 - 如果子节点的值大于父节点,
largest将记录最大值的索引 - 如果发现最大值的索引不是当前考察的父节点,则通过
swap交换当前节点和最大值的节点 - 由于交换后影响了子堆的结构,所以递归调用
maxHeapify来调整变动后的子堆,确保它仍然是最大堆
- 该函数接收一个索引
swap函数这个简单的函数通过解构赋值交换数组中两个元素的位置
- 实现数组
arr中索引i和j上的两个元素的交换。这种写法是ES6语法糖,是交换元素的快捷方式
- 实现数组
这整个堆排序的过程:
首先,通过 buildMaxHeap 将数组重新排序成最大堆
然后,堆顶(也是整个数组中的最大值)和数组的最后一个元素交换位置,然后缩小考察的数组范围(即 减少 heapSize),由于交换破坏了最大堆的属性,需要重新调用 maxHeapify 来恢复最大堆
重复这个过程,直到整个数组完全排序
最终,原数组 arr 变成已排序的数组,并返回
由于堆排序的方法,我们每次都能确定最大的元素被放置在最终的位置,因此不需要额外的存储空间之外的数组来进行排序
答案
1 | function heapSort(arr) { |
Q48:怎么实现一个二维码登录pc网站
难度:⭐⭐⭐⭐
答案
二维码登录是现代Web开发中常见的一种身份验证方式,尤其在移动设备广泛使用的背景下
它提供了一个便捷的方法,允许用户通过扫描二维码来登录PC网站,避免了手动输入账号密码的麻烦
接下来,我将详细解释二维码的本质及如何实现二维码登录PC网站
二维码的本质
二维码(Quick Response Code, QR Code)是一种矩阵二维码或二维条码,它由黑白色块组成
与传统的一维条码相比,二维码可以存储更多信息,包括网址、文本或其他数据
二维码可以通过相机扫描进行读取,这一点在二维码登录中尤为重要
实现二维码登录的流程
实现二维码登录通常涉及后端服务器、PC网站(通常是网站的登录页面)和用户的移动设备
基本流程大致如下:
生成登录二维码
在PC网站登录页面生成二维码
当用户打开PC网站的登录页面时,网站后台会生成一个唯一标识(通常是一个随机生成的字符串或UUID),并将这个唯一标识与一个登录请求的URL合并
然后,使用这个URL生成二维码显示在登录页面上
移动设备扫描二维码
用户使用移动设备扫描二维码
这一步通常需要用户已经在移动设备上登录了相应的移动应用(比如微信、支付宝等),应用可以识别并处理扫描到的URL
移动设备请求登录授权
移动应用处理二维码中的URL,向服务器发起登录授权请求
在这一步,移动应用通常会向服务器发送包含用户凭据(如令牌)和二维码中的唯一标识的请求
服务器验证并授权登录
服务器验证请求
服务器接收到登录授权请求后,验证用户凭据和唯一标识
如果验证成功,服务器则认为PC端的登录请求是合法的
通知PC端登录成功
服务器通过WebSocket或轮询机制通知PC端
一旦服务器验证用户成功,并且授权了PC端的登录请求,它需要一个方式来通知PC端
这通常通过WebSocket连接实现,如果PC端在生成二维码时就建立了WebSocket连接
或者通过PC端定期轮询服务器来检查登录状态
PC端完成登录
PC端接收到登录成功的通知后,完成登录过程
这可能涉及到设置用户的登录状态、储存令牌和跳转到登录后的页面等
关键技术实现
二维码生成
可以使用各种前端库来在网页上生成二维码,例如
qrcode.jsWebSocket或轮询
WebSocket提供了一个实时双向通信方案,使得服务器可以实时通知PC网站
如果不使用WebSocket,可以采用定时轮询的方式,让PC端定时向服务器发起请求查询登录状态
唯一标识处理
在服务器端生成并处理唯一标识(比如UUID),将它与用户的登录状态关联起来
安全性
确保所有通信都通过HTTPS进行,保护用户数据安全
另外,二维码的有效期应该设定得短些,避免被滥用
通过上述流程和关键技术实现点,你可以在自己的PC网站上实现二维码登录功能
这种登录方式为用户提供了便利的同时,也要确保整个过程的安全性
Q49:Javascript里面的倒计时怎么纠正偏差
难度:⭐⭐⭐⭐
答案
使用服务器时间作为基准
因为用户的设备时间可能不准确,所以最好在倒计时开始时同步一次服务器时间,并据此进行后续的倒计时计算
AJAX请求
通过一个异步请求获取服务器时间,并存储这个时间用于后续计算
1
2
3
4
5
6
7function getServerTime(callback) {
fetch('/api/server-time')
.then(response => response.json())
.then(data => {
callback(data.serverTime); // 服务器的UNIX时间戳
});
}WebSocket连接
维持一个WebSocket连接,动态同步服务器时间用于精确计时
1
2
3
4
5// 假设已经打开了一个WebSocket连接ws
ws.onmessage = function(event) {
const serverTime = JSON.parse(event.data).serverTime;
startCountdown(serverTime);
};
校正时间间隔
使用
setTimeout或setInterval的周期性调用可以不断校正时间,避免累计误差每次回调时应该重新计算剩余时间,而不是简单依赖固定的间隔
递归
setTimeout调用:使用setTimeout代替setInterval,并在每次回调执行时递归地调用它,实现自调正的特性1
2
3
4
5
6
7
8
9
10function countdown(remaining) {
if (remaining <= 0) {
console.log('Countdown finished');
return;
}
console.log(remaining + ' ms remaining');
setTimeout(() => countdown(remaining - 1000), 1000);
}
countdown(10000);动态延迟:在
setTimeout中动态计算下一次回调的延迟时间1
2
3
4
5
6
7
8
9function adaptiveCountdown(endTime) {
function scheduleNextTick() {
var now = Date.now();
var remaining = endTime - now;
var nextTick = remaining % 1000 || 1000;
setTimeout(scheduleNextTick, nextTick);
}
scheduleNextTick();
}
避免长时间间隔
尽量不要设置很长的单次倒计时(如几分钟以上),因为更长的时间间隔意味着更大的潜在偏差
如果需要长时间倒计时,应该分成多个较短的间隔
分段计时
将长时间间隔分成多个短时间间隔,逐段计时
1
2
3
4
5
6
7
8
9
10
11
12
13
14function segmentCountdown(duration, segment) {
var segmentsLeft = Math.ceil(duration / segment);
function tick() {
segmentsLeft--;
if (segmentsLeft > 0) {
setTimeout(tick, segment);
} else {
console.log('Countdown finished');
}
}
setTimeout(tick, segment);
}
使用性能优化
确保倒计时函数的执行尽可能快和轻量,减少其他JavaScript任务对倒计时精度的影响
降低页面复杂度
确保倒计时期间页面尽可能简洁,减少DOM操作和CPU密集型任务
使用
requestAnimationFrame这通常用于动画,但可以确保计时器的代码在浏览器绘图前执行,从而保持同步
1
2
3
4
5
6
7
8
9
10
11function frameCountdown(targetTime) {
function frame() {
var now = Date.now();
if (targetTime > now) {
requestAnimationFrame(frame);
} else {
console.log('Countdown finished');
}
}
requestAnimationFrame(frame);
}
使用Web Workers
如果需要高精度计时器,可以使用Web Workers,因为它们运行在后台线程,不受主线程任务的干扰
Dedicated Worker
创建一个独立的脚本文件,该文件作为Web Worker运行,用于倒计时
这个Dedicated Worker脚本接收来自主线程的倒计时开始指令,然后每秒通过
postMessage方法更新剩余时间,直至倒计时结束1
2
3
4
5
6
7
8
9
10
11
12
13// 接收主线程消息,开始倒计时
onmessage = function(event) {
var seconds = event.data;
var countdown = function() {
postMessage(seconds);
if(seconds-- > 0) {
setTimeout(countdown, 1000);
}
};
countdown();
};在主线程处理倒计时逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14// 创建Dedicated Worker
var countdownWorker = new Worker('countdownWorker.js');
// 接收Worker发来的倒计时数据
countdownWorker.onmessage = function(event) {
console.log("剩余时间: " + event.data + "秒");
if(event.data === 0) {
console.log("倒计时结束!");
countdownWorker.terminate(); // 停止Worker
}
};
// 启动倒计时,比如60秒
countdownWorker.postMessage(60);Shared Worker
如果需要在多个标签页或者iframe中共享同一个倒计时,可以使用Shared Worker来实现
主线程代码
只需要一处(例如,用户打开的第一个标签页)通过
postMessage启动倒计时,其他所有连接了这个Shared Worker的标签页都会收到倒计时更新的消息1
2
3
4
5
6
7
8
9
10
11
12
13var mySharedWorker = new SharedWorker('sharedCountdownWorker.js');
mySharedWorker.port.start();
mySharedWorker.port.onmessage = function(e) {
console.log("剩余时间: " + e.data + "秒");
if(e.data === 0) {
console.log("倒计时结束!");
}
};
// 只在一个标签页中启动倒计时即可
// mySharedWorker.port.postMessage(60);这个Shared Worker脚本接收来自任一连接它的页面的倒计时开始指令,然后每秒通过
postMessage给所有连接的端口更新剩余时间,实现多标签页或iframe间的倒计时共享1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20var ports = [];
onconnect = function(e) {
var port = e.ports[0];
ports.push(port);
port.onmessage = function(event) {
var seconds = event.data;
countdown(seconds);
};
};
function countdown(seconds) {
ports.forEach(port => {
port.postMessage(seconds);
});
if(seconds-- > 0) {
setTimeout(() => countdown(seconds), 1000);
}
}
引申
前端JavaScript获取的时间实际上是来自用户设备的系统时间,这意味着如果用户修改了设备的时间,那么JavaScript获取的时间也会受到影响,倒计时和其他依赖时间的功能会因此而不准确
Q50:实现合并Promise函数
实现mergePromise函数,把传进去的数组按顺序先后执行,并且把返回的数据先后放到数组data中
难度:⭐⭐⭐⭐
1 | const time = (timer) => { |
解析
promise方式
为了实现
mergePromise函数,我们需要按照传入数组的顺序依次执行这些异步操作,并收集每个异步操作的结果这可以通过链式调用Promise的
.then()方法来完成在这个实现中,
mergePromise函数接受一个包含ajax函数的数组ajaxArray我们定义了
data数组来保存每个ajax调用后resolve的结果我们开始时有一个“空”的已经resolved的Promise对象,我们把这个Promise对象赋值给
sequence变量然后我们利用
Array.prototype.forEach遍历ajaxArray数组,将数组中的每个函数加到sequence的调用链中,并通过连续调用.then()保证顺序执行在每一次迭代中,我们都将上一个Promise通过
.then()链接到当前的ajax调用,然后在另一个.then()中将结果res推入data数组,并返回data数组,这样下一个Promise的.then()可以接收到上一个.then()返回的数据数组这样遍历之后,
data数组就按顺序积累了所有ajax调用的结果最后返回的
sequencePromise在所有的ajax函数都顺序执行并且它们的结果都被推入data数组之后,就会被resolve这个最后的Promise resolve了
data数组作为结果,然后我们在.then()回调函数中打印出”data”数组和”done”利用这种方式,我们实现了函数依次执行,并按序收集它们resolve的值
await方式
也可以使用
async/await来实现使用
async/await可以让我们的代码看起来更像同步代码,降低了复杂性在此实现中,我们使用
async关键字声明了一个异步函数mergePromise,此函数接受一个包含ajax函数的数组ajaxArray在异步函数内部,我们可以使用
await关键字来等待每个ajax函数的完成,并将结果push进data数组这种方式的优点是,代码更简洁,更易于阅读
我们没有必要手动创建一个Promise链,可以直接在for循环中循环等待每个Promise的resolve,一旦全部完成,我们便得到了所有值放在
data数组中然后返回这个数组,当所有ajax调用都结束后,将会resolve整个
mergePromise函数的Promise
答案
promise方式
1 | function mergePromise(ajaxArray) { |
await方式
1 | async function mergePromise(ajaxArray) { |
Q51:使用Promise实现,限制异步并发个数,并尽快完成
有8个图片资源的url,已经存储在数组urls中
urls类似于['https://image1.png', 'https://image2.png', ....] 而且已经有一个函数function loadImg,输入一个url链接,返回一个Promise,该Promise在图片下载完成的时候resolve,下载失败则reject。
但有一个要求,任何时刻同时下载的链接数量不可以超过3个
请写一段代码实现这个需求,要求尽可能快速地将所有图片下载完成
难度:⭐⭐⭐⭐⭐
1 | var urls = [ |
解析
可以考虑使用”并发控制”的模式,即每次并发请求的数量为3,当有请求完成后再发起新的请求,直到全部图片都加载完成
这样可以确保任何时刻最多只有3个请求在同时进行
这段代码实现了一个名为 limitLoad 的函数,其目的是管理对图片资源的异步加载,限制在任何时刻同时进行的加载数量不超过给定的限制值(limit)
下面是对这个函数如何工作的逐步解析:
输入参数
urls一个包含图片资源URLs的数组
loadImg一个接受单个URL为参数并返回一个
Promise的函数,该Promise会在相应的图片加载完成时解决,如果加载失败,则拒绝limit同时进行图片加载的最大数量
函数执行流程
- 初始化变量
sequence: 通过复制urls数组创建,以避免修改原始数组promises: 存储正在进行的、数量不超过limit的加载操作的Promise对象数组
- 启动初始的并发请求
- 使用
map函数从sequence中提取前limit个URL,并对每个URL调用loadImg函数,开始加载对应的图片 - 对
loadImg返回的每个Promise,通过then和catch确保无论成功还是失败都将返回resolving的Promise,其中包含了该次加载操作在promises数组中的索引
- 使用
- 利用
reduce顺序处理剩余的urlsreduce通过一个初始的Promise开始执行,并且为序列中的每个URL顺序安排加载操作- 在每次迭代中,使用
Promise.race等待promises数组中任意一个Promise完成(无论是解决还是拒绝) - 一旦有
Promise完成,就用新的加载操作的Promise替换promises数组中对应的位置,这样可以确保promises数组始终在维护最多limit个正在进行的加载操作
- 处理所有加载操作完成后的情况
- 使用
promiseChain.then()等待所有通过reduce安排的加载操作完成 - 再通过
Promise.all(promises)等待当前正在进行的所有加载操作的完成 - 之后,通过
then()可以执行一些所有图片加载尝试完成(无论成功或失败)后的最终处理
- 使用
- 错误处理
- 在最后,通过
catch捕获整个加载过程中遇到的任何错误,并打印错误信息
- 在最后,通过
- 初始化变量
答案
1 | function limitLoad(urls, loadImg, limit) { |
实现API
Q1:使用 setTimeout 实现 setlnterval
难度:⭐⭐⭐
解析
在使用setTimeout实现setInterval(即模拟周期性执行某个函数的行为)的时候,核心思想是通过递归调用setTimeout来达到setInterval的效果
这么做有几个关键的注意点和技巧:
精确的时间控制
使用
setTimeout递归调用的方式可以比setInterval提供更精确的时间控制因为
setInterval在某些情况下可能会受到多个待执行的回调函数堆积的影响,导致实际执行间隔不准确在递归调用
setTimeout时,每次都是在上一个调用完成后才设置下一个调用,从一定程度上避免了这个问题避免堆积
在高负载或者执行时间较长的情况下,避免回调函数的堆积。如果回调函数执行时间过长,超过了设置的间隔时间,
setTimeout会等待回调函数执行完毕后立即执行,不会像setInterval那样导致回调函数堆积。错误处理
递归调用时,可以在每一次的回调函数中添加错误处理逻辑
这是利用
setTimeout模拟setInterval可以做到而直接使用setInterval较难实现的提供停止机制
在直接使用
setInterval时,可以通过clearInterval停止执行在用
setTimeout模拟时,需要手动提供一个机制来停止循环(比如,通过一个标志变量控制)性能考虑
虽然使用
setTimeout递归可以提供更灵活的控制,但在某些极端情况下(比如,非常短的时间间隔和复杂的业务逻辑),它可能会导致性能问题因此,设计时应考虑到具体的业务需求和环境
答案
1 | function mySetInterval(fn, timeout) { |
Q5:实现js里面的sort排序
难度:⭐⭐⭐⭐⭐
答案
1 | function quickSort(arr, compareFn = defaultCompare) { |
 wechat
wechat alipay
alipay










